oracle 1z0-449 practice test
Oracle Big Data 2016 Implementation Essentials
Question 1
You need to place the results of a PigLatin script into an HDFS output directory.
What is the correct syntax in Apache Pig?
A. update hdfs set D as ‘./output’;
B. store D into ‘./output’;
C. place D into ‘./output’;
D. write D as ‘./output’;
E. hdfsstore D into ‘./output’;
Answer:
B
Use the STORE operator to run (execute) Pig Latin statements and save (persist) results to the file
system. Use STORE for production scripts and batch mode processing.
STORE alias INTO 'directory' [USING function];
In this example data is stored using PigStorage and the asterisk character (*) as the field
delimiter.
int);
DUMP A;
(1,2,3)
(4,2,1)
(8,3,4)
(4,3,3)
(7,2,5)
(8,4,3)
STORE A INTO 'myoutput' USING PigStorage ('*');
CAT myoutput;
1*2*3
4*2*1
8*3*4
4*3*3
7*2*5
8*4*3
//pig.apache.org/docs/r0.13.0/basic.html#store
Question 2
How is Oracle Loader for Hadoop (OLH) better than Apache Sqoop?
A. OLH performs a great deal of preprocessing of the data on Hadoop before loading it into the
database.
B. OLH performs a great deal of preprocessing of the data on the Oracle database before loading it
into NoSQL.
C. OLH does not use MapReduce to process any of the data, thereby increasing performance.
D. OLH performs a great deal of preprocessing of the data on the Oracle database before loading it
into Hadoop.
E. OLH is fully supported on the Big Data Appliance. Apache Sqoop is not supported on the Big Data
Appliance.
Answer:
A
Oracle Loader for Hadoop provides an efficient and high-performance loader for fast movement of
data from a Hadoop cluster into a table in an Oracle database. Oracle Loader for Hadoop
prepartitions the data if necessary and transforms it into a database-ready format. It optionally sorts
records by primary key or user-defined columns before loading the data or creating output files.
Apache Sqoop(TM) is a tool designed for efficiently transferring bulk data between Apache
Hadoop and structured datastores such as relational databases.
Question 3
Which three pieces of hardware are present on each node of the Big Data Appliance? (Choose three.)
A. high capacity SAS disks
B. memory
C. redundant Power Delivery Units
D. InfiniBand ports
E. InfiniBand leaf switches
Answer:
A,B,D
//www.oracle.com/technetwork/server-storage/engineered-systems/bigdata-
appliance/overview/bigdataappliancev2-datasheet-1871638.pdf
Question 4
What two actions do the following commands perform in the Oracle R Advanced Analytics for
Hadoop Connector? (Choose two.)
ore.connect (type=”HIVE”)
ore.attach ()
A. Connect to Hive.
B. Attach the Hadoop libraries to R.
C. Attach the current environment to the search path of R.
D. Connect to NoSQL via Hive.
Answer:
A,C
You can connect to Hive and manage objects using R functions that have an ore prefix, such as
ore.connect.
ore.attach()
//docs.oracle.com/cd/E49465_01/doc.23/e49333/orch.htm#BDCUG400
Question 5
Your customer’s security team needs to understand how the Oracle Loader for Hadoop Connector
writes data to the Oracle database.
Which service performs the actual writing?
A. OLH agent
B. reduce tasks
C. write tasks
D. map tasks
E. NameNode
Answer:
B
Oracle Loader for Hadoop has online and offline load options. In the online load option, the data is
both preprocessed and loaded into the database as part of the Oracle Loader for Hadoop job. Each
reduce task makes a connection to Oracle Database, loading into the database in parallel. The
database has to be available during the execution of Oracle Loader for Hadoop.
//www.oracle.com/technetwork/bdc/hadoop-loader/connectors-hdfs-wp-1674035.pdf
Question 6
Your customer needs to manage configuration information on the Big Data Appliance.
Which service would you choose?
A. SparkPlug
B. ApacheManager
C. Zookeeper
D. Hive Server
E. JobMonitor
Answer:
C
The ZooKeeper utility provides configuration and state management and distributed coordination
services to Dgraph nodes of the Big Data Discovery cluster. It ensures high availability of the query
processing by the Dgraph nodes in the cluster.
//docs.oracle.com/cd/E57471_01/bigData.100/admin_bdd/src/cadm_cluster_zookeeper.html
Question 7
You are helping your customer troubleshoot the use of the Oracle Loader for Hadoop Connector in
online mode. You have performed steps 1, 2, 4, and 5.
STEP 1: Connect to the Oracle database and create a target table.
STEP 2: Log in to the Hadoop cluster (or client).
STEP 3: Missing step
STEP 4: Create a shell script to run the OLH job.
STEP 5: Run the OLH job.
What step is missing between step 2 and step 4?
- A. Diagnose the job failure and correct the error.
- B. Copy the table metadata to the Hadoop system.
- C. Create an XML configuration file.
- D. Query the table to check the data.
- E. Create an OLH metadata file.
Answer:
C
Question 8
The hdfs_stream script is used by the Oracle SQL Connector for HDFS to perform a specific task to
access dat
a.
What is the purpose of this script?
A. It is the preprocessor script for the Impala table.
B. It is the preprocessor script for the HDFS external table.
C. It is the streaming script that creates a database directory.
D. It is the preprocessor script for the Oracle partitioned table.
E. It defines the jar file that points to the directory where Hive is installed.
Answer:
B
The hdfs_stream script is the preprocessor for the Oracle Database external table created by Oracle
SQL Connector for HDFS.
//docs.oracle.com/cd/E37231_01/doc.20/e36961/start.htm#BDCUG107
Question 9
How should you encrypt the Hadoop data that sits on disk?
A. Enable Transparent Data Encryption by using the Mammoth utility.
B. Enable HDFS Transparent Encryption by using bdacli on a Kerberos-secured cluster.
C. Enable HDFS Transparent Encryption on a non-Kerberos secured cluster.
D. Enable Audit Vault and Database Firewall for Hadoop by using the Mammoth utility.
Answer:
B
HDFS Transparent Encryption protects Hadoop data that’s at rest on disk. When the encryption is
enabled for a cluster, data write and read operations on encrypted zones (HDFS directories) on the
disk are automatically encrypted and decrypted. This process is “transparent” because it’s invisible to
the application working with the data.
The cluster where you want to use HDFS Transparent Encryption must have Kerberos enabled.
Question 10
What two things does the Big Data SQL push down to the storage cell on the Big Data Appliance?
(Choose two.)
- A. Transparent Data Encrypted data
- B. the column selection of data from individual Hadoop nodes
- C. WHERE clause evaluations
- D. PL/SQL evaluation
- E. Business Intelligence queries from connected Exalytics servers
Answer:
A,B
Question 11
You want to set up access control lists on your NameNode in your Big Data Appliance. However,
when you try to do so, you get an error stating “the NameNode disallows creation of ACLs.”
What is the cause of the error?
A. During the Big Data Appliance setup, Cloudera's ACLSecurity product was not installed.
B. Access control lists are set up on the DataNode and HadoopNode, not the NameNode.
C. During the Big Data Appliance setup, the Oracle Audit Vault product was not installed.
D. dfs.namenode.acls.enabled must be set to true in the NameNode configuration.
Answer:
D
To use ACLs, first you’ll need to enable ACLs on the NameNode by adding the following configuration
property to hdfs-site.xml and restarting the NameNode.
<property>
<name>dfs.namenode.acls.enabled</name>
<value>true</value>
</property>
//hortonworks.com/blog/hdfs-acls-fine-grained-permissions-hdfs-files-hadoop/
Question 12
Your customer has an older starter rack Big Data Appliance (BDA) that was purchased in 2013. The
customer would like to know what the options are for growing the storage footprint of its server.
Which two options are valid for expanding the customer’s BDA footprint? (Choose two.)
- A. Elastically expand the footprint by adding additional high capacity nodes.
- B. Elastically expand the footprint by adding additional Big Data Oracle Database Servers.
- C. Elastically expand the footprint by adding additional Big Data Storage Servers.
- D. Racks manufactured before 2014 are no longer eligible for expansion.
- E. Upgrade to a full 18-node Big Data Appliance.
Answer:
D,E
Question 13
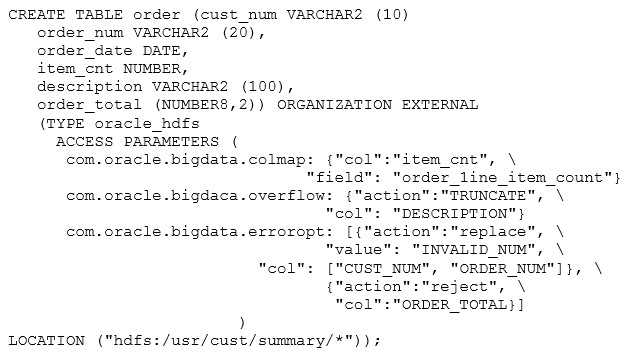
What are three correct results of executing the preceding query? (Choose three.)
A. Values longer than 100 characters for the DESCRIPTION column are truncated.
B. ORDER_LINE_ITEM_COUNT in the HDFS file matches ITEM_CNT in the external table.
C. ITEM_CNT in the HDFS file matches ORDER_LINE_ITEM_COUNT in the external table.
D. Errors in the data for CUST_NUM or ORDER_NUM set the value to INVALID_NUM.
E. Errors in the data for CUST_NUM or ORDER_NUM set the value to 0000000000.
F. Values longer than 100 characters for any column are truncated.
Answer:
A,C,D
Truncates string data. Values longer than 100 characters for the
DESCRIPTION column are truncated.
Truncates string data. Values longer than 100 characters for the
DESCRIPTION column are truncated.
Replaces bad data. Errors in the data for CUST_NUM or ORDER_NUM
set the value to INVALID_NUM.
//docs.oracle.com/cd/E55905_01/doc.40/e55814/bigsql.htm#BIGUG76679
Question 14
What does the following line do in Apache Pig?
products = LOAD ‘/user/oracle/products’ AS (prod_id, item);
A. The products table is loaded by using data pump with prod_id and item.
B. The LOAD table is populated with prod_id and item.
C. The contents of /user/oracle/products are loaded as tuples and aliased to products.
D. The contents of /user/oracle/products are dumped to the screen.
Answer:
C
The LOAD function loads data from the file system.
LOAD 'data' [USING function] [AS schema];
'data'
The name of the file or directory, in single quote
//pig.apache.org/docs/r0.11.1/basic.html#load
Question 15
What is the output of the following six commands when they are executed by using the Oracle XML
Extensions for Hive in the Oracle XQuery for Hadoop Connector?
1. $ echo "xxx" > src.txt
2. $ hive --auxpath $OXH_HOME/hive/lib -i $OXH_HOME/hive/init.sql
3. hive> CREATE TABLE src (dummy STRING);
4. hive> LOAD DATA LOCAL INPATH 'src.txt' OVERWRITE INTO TABLE src;
5. hive> SELECT * FROM src;
OK
xxx
6. hive> SELECT xml_query ("x/y", "<x><y>123</y><z>456</z></x>") FROM src;
A. xyz
B. 123
C. 456
D. xxx
E. x/y
Answer:
B
Using the Hive Extensions
To enable the Oracle XQuery for Hadoop extensions, use the --auxpath and -i arguments when
$ hive --auxpath $OXH_HOME/hive/lib -i $OXH_HOME/hive/init.sql
The first time you use the extensions, verify that they are accessible. The following procedure creates
a table named SRC, loads one row into it, and calls the xml_query function.
//docs.oracle.com/cd/E53356_01/doc.30/e53067/oxh_hive.htm#BDCUG693