oracle 1z0-1084-21 practice test
Oracle Cloud Infrastructure Developer 2021 Associate Exam
Question 1
What is the communication method between different Cloud native applications services?
- A. Complex and asynchronous
- B. Basic and synchronous
- C. Complex and synchronous
- D. Basic and asynchronous
Answer:
D
Explanation:
What Is Cloud Native?
Cloud native technologies are characterized by the use of containers, microservices, serverless
functions, development pipelines, infrastructure expressed as code, event-driven applications, and
Application Programming Interfaces (APIs). Cloud native enables faster software development and
the ability to build applications that are resilient, manageable, observable, and dynamically scalable
to global enterprise levels.
When constructing a cloud-native application, you'll want to be sensitive to how back-end services
communicate with each other. Ideally, the less inter-service communication, the better. However,
avoidance isn't always possible as back-end services often rely on one another to complete an
operation.
While direct HTTP calls between microservices are relatively simple to implement, care should be
taken to minimize this practice. To start, these calls are alwayssynchronousand will block the
operation until a result is returned or the request times outs. What were once self-contained,
independent services, able to evolve independently and deploy frequently, now become coupled to
each other. As coupling among microservices increase, their architectural benefits diminish.
Executing an infrequent request that makes a single direct HTTP call to another microservice might
be acceptable for some systems. However, high-volume calls that invoke direct HTTP calls to multiple
microservices aren't advisable. They can increase latency and negatively impact the performance,
scalability, and availability of your system. Even worse, along series of direct HTTP communication
can lead to deep and complex chains of synchronous microservices calls,shown in Figure 4-9: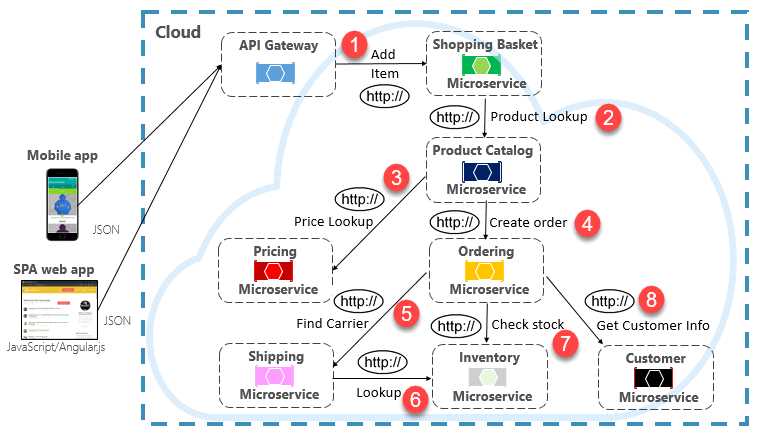
A message queue is an intermediary construct through which a producer and consumer pass a
message. Queuesimplement an asynchronous, point-to-point messaging pattern.
Events
Message queuingis an effective way to implement communication where a producer
canasynchronouslysend a consumer a message.
Reference:
https://www.xenonstack.com/blog/cloud-native-architecture/
https://www.oracle.com/sa/cloud/cloud-native/
https://www.oracle.com/technetwork/topics/entarch/cloud-native-app-development-wp-
3664668.pdf
Question 2
In a Linux environment, what is the default location of the configuration file that Oracle Cloud
Infrastructure CLI uses for profile information? (Choose the best answer.)
- A. $HOME/.oci/con
- B. /usr/local/bin/con
- C. /usr/bin/oci/con
- D. /etc/.oci/con
Answer:
A
Explanation:
Before using Oracle Functions, you must have an Oracle Cloud Infrastructure CLI configuration file
that contains the credentials of the user account that you will be using to create and deploy
functions. These user account credentials are referred to as a 'profile'.
By default, the Oracle Cloud Infrastructure CLI configuration file is located at~/.oci/config. You might
already have a configuration file as a result of installing the Oracle Cloud Infrastructure CLI. However,
you don't need to have installed the Oracle Cloud Infrastructure CLI in order to use Oracle Functions.
Reference:
https://docs.cloud.oracle.com/en-
us/iaas/Content/Functions/Tasks/functionsconfigureocicli.htm#:~:text=By%20default%2C%20the%2
0Oracle%20Cloud,file%20is%20located%20at%20~%2F.
https://docs.cloud.oracle.com/en-us/iaas/Content/API/SDKDocs/cliconfigure.htm
Question 3
Which pattern can help you minimize the probability of cascading failures in your system during
partial loss of connectivity or a complete service failure?
- A. Retry pattern
- B. Anti-corruption layer pattern
- C. Circuit breaker pattern
- D. Compensating transaction pattern
Answer:
C
Explanation:
Acascading failure is a failure that grows over time as a result of positive feedback. It can occur when
a portion of an overall system fails, increasing the probability that other portions of the system fail.
the circuit breaker pattern prevents the service from performing an operation that is likely to fail. For
example, a client service can use a circuit breaker to prevent further remote calls over the network
when a downstream service is not functioning properly. This can also prevent the network from
becoming congested by a sudden spike in failed retries by one service to another, and it can
alsoprevent cascading failures. Self-healing circuit breakers check the downstream service at regular
intervals and reset the circuit breaker when the downstream service starts functioning properly.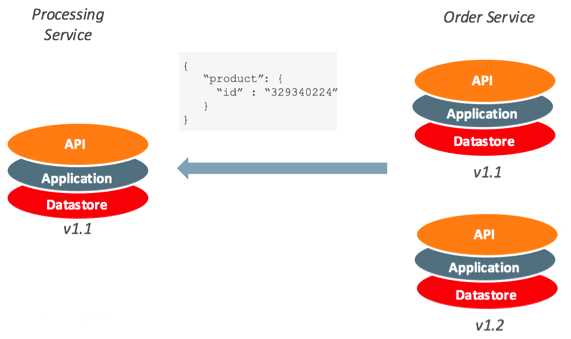
https://blogs.oracle.com/developers/getting-started-with-microservices-part-three
Question 4
Which two statements accurately describe Oracle SQL Developer Web on Oracle Cloud Infrastructure
(OCI) Autonomous Database?
- A. It is available for databases with dedicated Exadata infrastructure only.
- B. After provisioning into an OCI compute Instance, it can automatically connect to the OCI Autonomous Databases instances.
- C. It is available for databases with both dedicated and shared Exadata infrastructure.
- D. It provides a development environment and a data modeler interface for OCI Autonomous Databases.
- E. It must be enabled via OCI Identity and Access Management policy to get access to the Autonomous Databases instances.
Answer:
AD
Explanation:
Oracle SQLDeveloper Web
Oracle SQL Developer Web in Autonomous Data Warehouse provides a development environment
and a data modeler interface forAutonomous Databases. SQLDeveloper Web is available for
databases with both
dedicated Exadata infrastructure
and
shared Exadata infrastructure
.
https://docs.cloud.oracle.com/en-us/iaas/Content/Database/Tasks/adbtools.htm
Question 5
Which is NOT a supported SDK on Oracle Cloud Infrastructure (OCI)?
- A. Ruby SDK
- B. Java SDK
- C. Python SDK
- D. Go SDK
- E. .NET SDK
Answer:
E
Explanation:
https://docs.cloud.oracle.com/en-us/iaas/Content/API/Concepts/sdks.htm
Question 6
Given a service deployed on Oracle Cloud Infrastructure Container Engine far Kubernetes (OKE),
which annotation should you add in the sample manifest file below to specify a 400 Mbps load
balancer?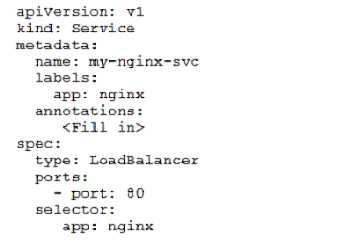
- A. service.beta.kubernetes.io/oci-load-balancer-value: 400Mbps
- B. service.beta.kubernetes.io/oci-load-balancer-size: 400Mbps
- C. service.beta.kubernetes.io/oci-load-balancer-shape: 400Mbps
- D. service, beta, kubernetes . io/oci-load—balancer-kind: 400Mbps
Answer:
C
Explanation:
Overview of Load Balancing:
SHAPE
A template that determines the load balancer's total pre-provisioned maximum capacity (bandwidth)
for ingress plus egress traffic. Available shapes include 10Mbps,100 Mbps,400 Mbps, and 8000
Mbps.
oci-load-balancer-shape:A template that determines the load balancer's total pre-provisioned
maximum capacity (bandwidth) for ingress plus egress traffic. Available shapes include 100Mbps,
400Mbps, and 8000Mbps. Cannot be modified after load balancer creation.
All annotations are prefixed withservice.beta.kubernetes.io/. For example:
kind: Service
apiVersion: v1
metadata:
name: nginx-service
annotations:
service.beta.kubernetes.io/oci-load-balancer-shape: "400Mbps"
service.beta.kubernetes.io/oci-load-balancer-subnet1: "ocid..."
service.beta.kubernetes.io/oci-load-balancer-subnet2: "ocid..."
spec:
...
Reference:
https://docs.cloud.oracle.com/en-us/iaas/Content/Balance/Concepts/balanceoverview.htm
https://github.com/oracle/oci-cloud-controller-manager/blob/master/docs/load-balancer-
annotations.md
Question 7
What is the minimum amount of storage that a persistent volume claim can obtain In Oracle Cloud
Infrastructure Container Engine for Kubemetes (OKE)?
- A. 1 TB
- B. 10 GB
- C. 1 GB
- D. 50 GB
Answer:
D
Explanation:
Provisioning Persistent Volume Claims on the Block Volume Service:
Block volume quota: If you intend to create Kubernetes persistent volumes, sufficient block volume
quota must be available in each availability domain to meet the persistent volume claim. Persistent
volume claims must request aminimum of 50 gigabytes.
Reference:
https://docs.cloud.oracle.com/en-
us/iaas/Content/ContEng/Tasks/contengcreatingpersistentvolumeclaim.htm
https://docs.cloud.oracle.com/en-us/iaas/Content/ContEng/Concepts/contengprerequisites.htm
Question 8
What is the difference between blue/green and canary deployment strategies?
- A. In blue/green, application Is deployed In minor increments to a select group of people. In canary, both old and new applications are simultaneously in production.
- B. In blue/green, both old and new applications are in production at the same time. In canary, application is deployed Incrementally to a select group of people.
- C. In blue/green, current applications are slowly replaced with new ones. In < MW y, Application ll deployed incrementally to a select group of people.
- D. In blue/green, current applications are slowly replaced with new ones. In canary, both old and new applications are In production at the same time.
Answer:
B
Explanation:
Blue-green deployment is a technique that reduces downtime and risk by running two identical
production environments called Blue and Green. At any time, only one of the environments is live,
with the live environment serving all production traffic. For this example, Blue is currently live and
Green is idle.
https://docs.cloudfoundry.org/devguide/deploy-apps/blue-green.html
Canary deployments are a pattern for rolling out releases to a subset of users or servers. The idea is
to first deploy the change to a small subset of servers, test it, and then roll the change out to the rest
of the servers. ... Canaries were once regularly used in coal mining as an early warning system.
https://octopus.com/docs/deployment-patterns/canary-deployments
Question 9
What is the open source engine for Oracle Functions?
- A. Apache OpenWhisk
- B. OpenFaaS
- C. Fn Project
- D. Knative
Answer:
C
Explanation:
https://www.oracle.com/webfolder/technetwork/tutorials/FAQs/oci/Functions-FAQ.pdf
Oracle Functions is a fully managed, multi-tenant, highly scalable, on-demand, Functions-as-a-
Service platform. It is built on enterprise-grade Oracle Cloud Infrastructure and powered by theFn
Projectopen source engine. Use Oracle Functions (sometimes abbreviated to just Functions) when
you want to focus on writing code to meet business needs.
Question 10
Which one of the following is NOT a valid backend-type supported by Oracle Cloud Infrastructure
(OCI) API Gateway?
- A. STOCK_RESPONSE_BACKEND
- B. ORACLE_FUNCTIONS_BACKEND
- C. ORACLE_STREAMS_BACKEND
- D. HTTP_BACKEND
Answer:
C
Explanation:
In the API Gateway service, a back end is the means by which a gateway routes requests to the back-
end services that implement APIs. If you add a private endpoint back end to an API gateway, you give
the API gateway access to the VCN associated with that private endpoint.
You can also grant an API gateway access to other Oracle Cloud Infrastructure services as back ends.
For example, you could grant an API gateway access to Oracle Functions, so you can create and
deploy an API that is backed by a serverless function.
API Gateway service to create an API gateway, you can create an API deployment to access HTTP and
HTTPS URLs.
https://docs.cloud.oracle.com/en-
us/iaas/Content/APIGateway/Tasks/apigatewayusinghttpbackend.htm
API Gateway service to create an API gateway, you can create an API deployment that invokes
serverless functions defined in Oracle Functions.
https://docs.cloud.oracle.com/en-
us/iaas/Content/APIGateway/Tasks/apigatewayusingfunctionsbackend.htm
API Gateway service, you can define a path to a stock response back end
https://docs.cloud.oracle.com/en-
us/iaas/Content/APIGateway/Tasks/apigatewayaddingstockresponses.htm
Question 11
What can you use to dynamically make Kubernetes resources discoverable to public DNS servers?
- A. ExternalDNS
- B. CoreDNS
- C. DynDNS
- D. kubeDNS
Answer:
A
Explanation:
Setting up ExternalDNS for Oracle Cloud Infrastructure (OCI):
Inspired by
Kubernetes DNS
, Kubernetes' cluster-internal DNS server, ExternalDNS makes Kubernetes
resources discoverable via public DNS servers. Like KubeDNS, it retrieves a list of resources (Services,
Ingresses, etc.) from the
Kubernetes API
to determine a desired list of DNS records.
In a broader sense,ExternalDNSallows you tocontrol DNS records dynamically via Kubernetes
resources in a DNS provider-agnostic way
Deploy ExternalDNS
Connect yourkubectlclient to the cluster you want to test ExternalDNS with. We first need to create
a config file containing the information needed to connect with the OCI API.
Create a new file (oci.yaml) and modify the contents to match the example below. Be sure to adjust
the values to match your own credentials:
auth:
region: us-phoenix-1
tenancy: ocid1.tenancy.oc1...
user: ocid1.user.oc1...
key: |
-----BEGIN RSA PRIVATE KEY-----
-----END RSA PRIVATE KEY-----
fingerprint: af:81:71:8e...
compartment: ocid1.compartment.oc1...
Reference:
https://github.com/kubernetes-sigs/external-dns/blob/master/README.md
https://github.com/kubernetes-sigs/external-dns/blob/master/docs/tutorials/oracle.md
Question 12
You have deployed a Python application on Oracle Cloud Infrastructure Container Engine for
Kubernetes. However, during testing you found a bug that you rectified and created a new Docker
image. You need to make sure that if this new Image doesn't work then you can roll back to the
previous version.
Using kubectl, which deployment strategies should you choose?
- A. Rolling Update
- B. Canary Deployment
- C. Blue/Green Deployment
- D. A/B Testing
Answer:
C
Explanation:
Using Blue-Green Deployment to Reduce Downtime and Risk:
>Blue-green deploymentis a technique thatreduces downtime and risk by running two identical
production environments called Blue and Green. At any time, only one of the environments is live,
with the live environment serving all production traffic. For this example, Blue is currently live and
Green is idle.
This technique can eliminate downtime due to app deployment. In addition, blue-green deployment
reduces risk:if something unexpected happenswith yournew version on Green,you can
immediately roll backto thelast version by switching back to Blue.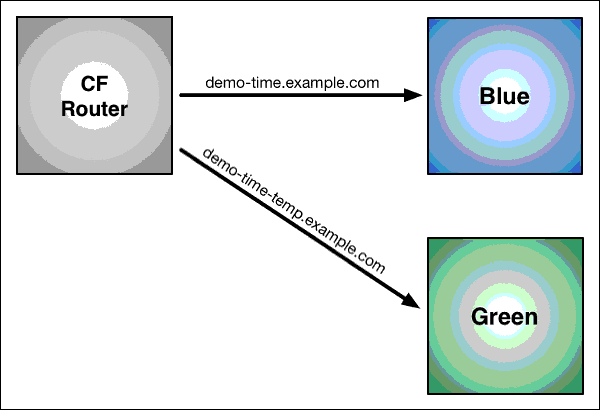
>Canary deploymentsare a pattern for rolling out releases to a subset of users or servers. The idea is
to first deploy the change to a small subset of servers, test it, and then roll the change out to the rest
of the servers. The canary deployment serves as an early warning indicator with less impact on
downtime: if the canary deployment fails, the rest of the servers aren't impacted.
>A/B testingis a way to compare two versions of a single variable, typically by testing a subject's
response to variant A against variant B, and determining which of the two variants is more effective
>Rolling updateoffers a way to deploy the new version of your application gradually across your
cluster.
Reference:
https://docs.cloudfoundry.org/devguide/deploy-apps/blue-green.html
Question 13
What are two of the main reasons you would choose to implement a serverless architecture?
- A. No need for integration testing
- B. Reduced operational cost
- C. Improved In-function state management
- D. Automatic horizontal scaling
- E. Easier to run long-running operations
Answer:
B, D
Explanation:
Serverless computing refers to a concept in which the user does not need to manage any server
infrastructure at all. The user does not run any servers, but instead deploys the application code to a
service providers platform. The application logic is executed,scaled, and billed on demand, without
any costs to the user when the application is idle.
Benefits of the Serverless or FaaS
So far almost every aspect of Serverless or FaaS is discussed in a brief, so lets talk about the pros and
cons of using Serverless or FaaS
Reduced operational and development cost
Serverless or FaaS offers less operational and development cost as it encourages to use third-party
services like Auth, Database and etc.
Scaling
Horizontal scaling in Serverless or FaaS is completely automatic, elastic and managed by FaaS
provider.If your application needs more requests to be processed in parallel the provider will take of
that without you providing any additional configuration.
Reference:
https://medium.com/@avishwakarma/serverless-or-faas-a-deep-dive-e67908ca69d5
https://qvik.com/news/serverless-faas-computing-costs/
https://pages.awscloud.com/rs/112-TZM-766/images/PTNR_gsc-serverless-ebook_Feb-2019.pdf
Question 14
Who is responsible for patching, upgrading and maintaining the worker nodes in Oracle Cloud
Infrastructure Container Engine for Kubernetes (OKE)?
- A. It Is automated
- B. Independent Software Vendors
- C. Oracle Support
- D. The user
Answer:
D
Explanation:
After a new version of Kubernetes has been released and when Container Engine for Kubernetes
supports the new version, you can use Container Engine for Kubernetes to upgrade master nodes
running older versions of Kubernetes. Because Container Engine for Kubernetes distributes the
Kubernetes Control Plane on multiple Oracle-managed master nodes (distributed across different
availability domains in a region where supported) to ensure high availability, you're able to upgrade
the Kubernetes version running on master nodes with zero downtime.
Having upgraded master nodes to a new version of Kubernetes, you can subsequently create new
node pools running the newer version. Alternatively, you can continue to create new node pools that
will run older versions of Kubernetes (providing those older versions are compatible with the
Kubernetes version running on the master nodes).
Note that you upgrade master nodes by performing an in-place upgrade, but you upgrade worker
nodes by performing an out-of-place upgrade. To upgrade the version of Kubernetes running on
worker nodes in a node pool, you replace the original node pool with a new node pool that has new
worker nodes running the appropriate Kubernetes version. Having 'drained' existing worker nodes in
the original node pool to prevent new pods starting and to delete existing pods, you can then delete
the original node pool.
Upgrading the Kubernetes Version on Worker Nodes in a Cluster:
After a new version of Kubernetes has been released and when Container Engine for Kubernetes
supports the new version, you can use Container Engine for Kubernetes to upgrade master nodes
running older versions of Kubernetes. Because Container Engine for Kubernetes distributes the
Kubernetes Control Plane on multiple Oracle-managed master nodes (distributed across different
availability domains in a region where supported) to ensure high availability, you're able to upgrade
the Kubernetes version running on master nodes with zero downtime.
You can upgrade the version of Kubernetes running on the worker nodes in a cluster in two ways:
(A) Perform an 'in-place' upgradeof a node pool in the cluster, by specifying a more recent
Kubernetes version for new worker nodes starting in the existing node pool. First, you modify the
existing node pool's properties to specify the more recent Kubernetes version. Then, you 'drain'
existing worker nodes in the node pool to prevent new pods starting, and to delete existing pods.
Finally, you terminate each of the worker nodes in turn. When new worker nodes are started in the
existing node pool, they run the more recent Kubernetes version you specified. See
Performing an In-
Place Worker Node Upgrade by Updating an Existing Node Pool
.
(B) Perform an 'out-of-place' upgradeof a node pool in the cluster, by replacing the original node
pool with a new node pool. First, you create a new node pool with a more recent Kubernetes version.
Then, you 'drain' existing worker nodes in the original node pool to prevent new pods starting, and to
delete existing pods. Finally, you delete the original node pool. When new worker nodes are started
in the new node pool, they run the more recent Kubernetes version you specified. See
Performing an
Out-of-Place Worker Node Upgrade by Replacing an Existing Node Pool with a New Node Pool
.
Note that in both cases:
The more recent Kubernetes version you specify for the worker nodes in the node pool must be
compatible with the Kubernetes version running on the master nodes in the cluster. See
Upgrading
Clusters to Newer Kubernetes Versions
).
You must drain existing worker nodes in the original node pool. If you don't drain the worker nodes,
workloads running on the cluster are subject to disruption.
Reference:
https://docs.cloud.oracle.com/en-
us/iaas/Content/ContEng/Tasks/contengupgradingk8sworkernode.htm
Question 15
Which two are benefits of distributed systems?
- A. Privacy
- B. Security
- C. Ease of testing
- D. Scalability
- E. Resiliency
Answer:
D, E
Explanation:
distributed systems of native-cloud like functions that have a lot of benefit like
Resiliency and availability
Resiliency and availability refers to the ability of a system to continue operating, despite the failure
or sub-optimal performance of some of its components.
In the case of Oracle Functions:
The control plane is a set of components that manages function definitions.
The data plane is a set of components that executes functions in response to invocation requests.
For resiliency and high availability, both the control plane and data plane components are distributed
across different availability domains and fault domains in a region. If one of the domains ceases to be
available, the components in the remaining domains take over to ensure that function definition
management and execution are not disrupted.
When functions are invoked, they run in the subnets specified for the application to which the
functions belong. For resiliency and high availability, best practice is to specify a regional subnet for
an application (or alternatively, multiple AD-specific subnets in different availability domains). If an
availability domain specified for an application ceases to be available, Oracle Functions runs
functions in an alternative availability domain.
Concurrency and Scalability
Concurrency refers to the ability of a system to run multiple operations in parallel using shared
resources. Scalability refers to the ability of the system to scale capacity (both up and down) to meet
demand.
In the case of Functions, when a function is invoked for the first time, the function's image is run as a
container on an instance in a subnet associated with the application to which the function belongs.
When the function is executing inside the container, the function can read from and write to other
shared resources and services running in the same subnet (for example, Database as a Service). The
function can also read from and write to other shared resources (for example, Object Storage), and
other Oracle Cloud Services.
If Oracle Functions receives multiple calls to a function that is currently executing inside a running
container, Oracle Functions automatically and seamlessly scales horizontally to serve all the incoming
requests. Oracle Functions starts multiple Docker containers, up to the limit specified for your
tenancy. The default limit is 30 GB of RAM reserved for function execution per availability domain,
although you can request an increase to this limit. Provided the limit is not exceeded, there is no
difference in response time (latency) between functions executing on the different containers.