Nutanix ncp-mci-6-10 practice test
Nutanix Certified Professional - Multicloud Infrastructure v6.10
Question 1
The customer expects to maintain a cluster runway of 9 months. The customer doesn’t have a budget
for 6 months but they want to add new workloads to the existing cluster.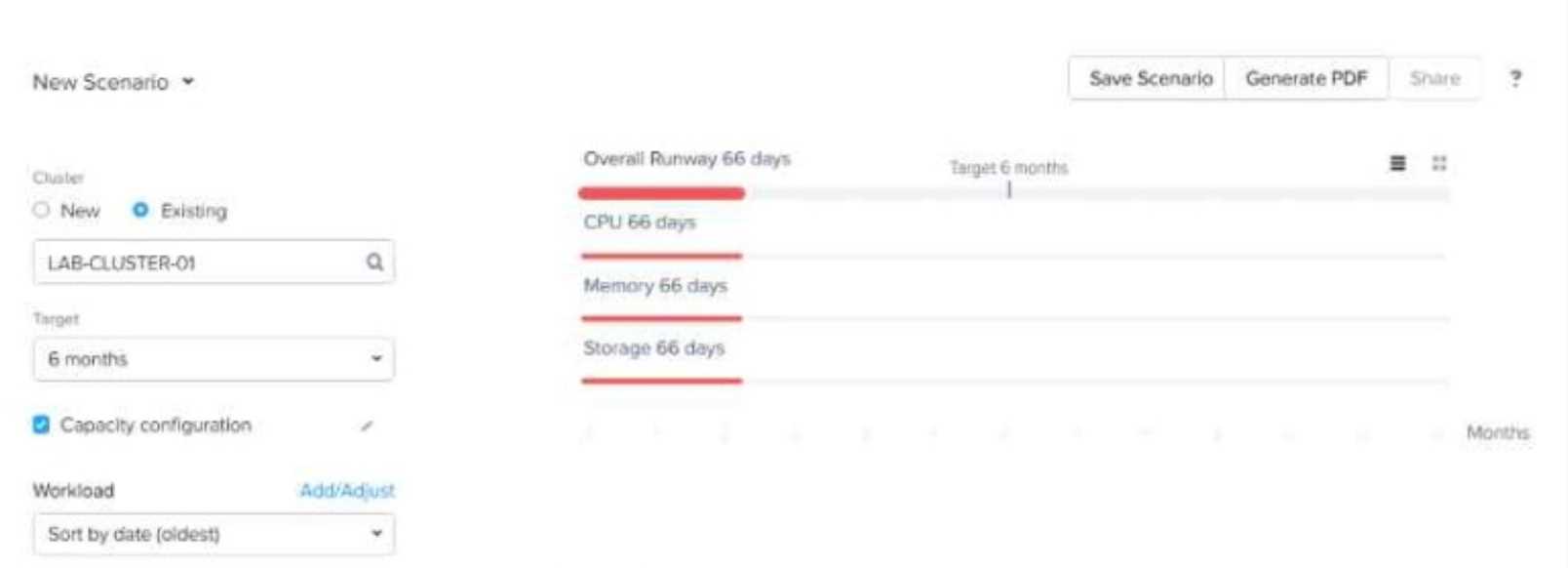
Based on the exhibit, what is required to meet the customer's budgetary timeframe?
- A. Add resources to the cluster.
- B. Postpone the start of new workloads.
- C. Delete workloads running on the cluster.
- D. Change the target to 9 months.
Answer:
B
Question 2
An administrator is trying to configure Metro Availability between Nutanix ESXi-based clusters.
However, the Compatible Remote Sites screen does not list all required storage containers.
Which two reasons could be a cause for this issue? (Choose two.)
- A. Source and destination hardware are from different vendors.
- B. The remote site storage container has compression enabled.
- C. The destination storage container is not empty.
- D. Both storage containers must have the same name.
Answer:
B, D
Question 3
An administrator receives complaints about VM performance.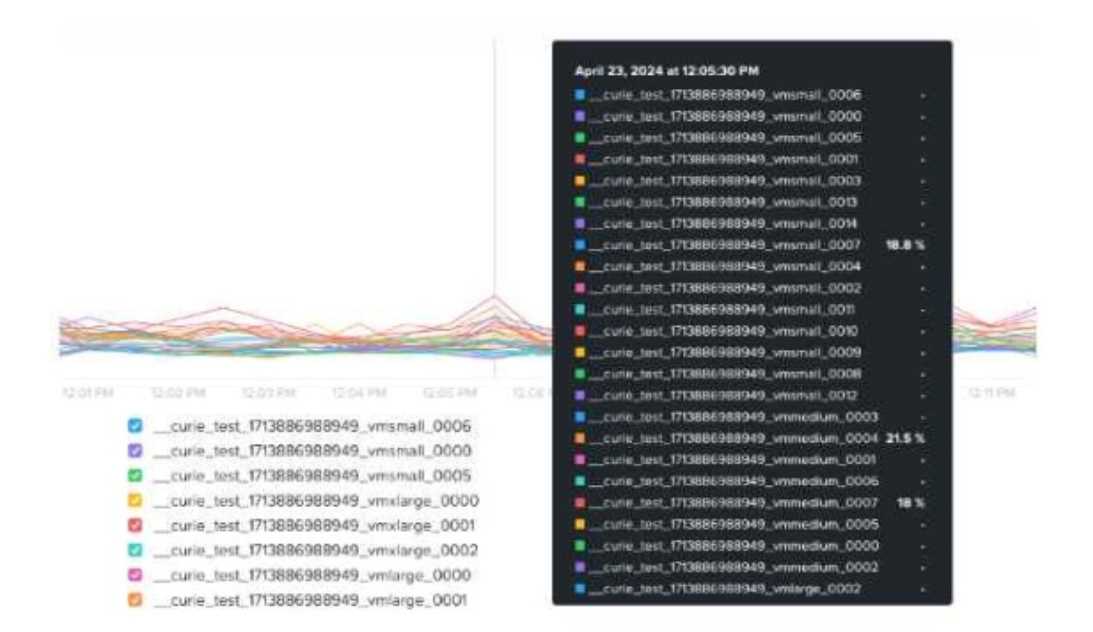
After reviewing the VM’s CPU Ready Time data shown in the exhibit, which step should the
administrator take to diagnose the issue further?
- A. Check the number of vCPUs assigned to each CVM.
- B. Review host CPU utilization.
- C. Assess cluster SSD capacity.
- D. Enable VM memory oversubscription.
Answer:
B
Explanation:
Understanding the Issue
The administrator is investigating VM performance complaints and is analyzing CPU Ready Time
data.
CPU Ready Time is a crucial metric in Nutanix and virtualization environments (AHV, ESXi, or Hyper-
V).
It measures the amount of time a VM is waiting for CPU scheduling due to resource contention.
High CPU Ready Time indicates that VMs are ready to run but are waiting because the host lacks
available CPU resources.
Analysis of the Exhibit
The graph shows CPU Ready Time spikes for multiple VMs.
Some VMs have CPU Ready Time exceeding 18% to 21.5%, which is very high.
A healthy CPU Ready Time should be below 5%.
Values above 10% indicate CPU contention, and anything above 20% is critical and requires
immediate troubleshooting.
Evaluating the Answer Choices
❌
(A) Check the number of vCPUs assigned to each CVM. (Incorrect)
CVMs (Controller VMs) have fixed CPU allocation, and modifying their vCPU count is not
recommended unless advised by Nutanix Support.
The issue is related to VM CPU contention, not CVM configuration.
✅
(B) Review host CPU utilization. (Correct Answer)
High CPU Ready Time suggests CPU overcommitment or host saturation.
The administrator should check host CPU usage in Prism Central to determine if the cluster is
overloaded.
If host CPU usage is consistently above 85–90%, VMs are competing for CPU resources, leading to
high CPU Ready Time.
❌
(C) Assess cluster SSD capacity. (Incorrect)
SSD capacity impacts storage performance (latency, read/write speeds) but does not affect CPU
Ready Time.
High CPU Ready Time is a CPU scheduling issue, not a storage bottleneck.
❌
(D) Enable VM memory oversubscription. (Incorrect)
Memory oversubscription does not impact CPU scheduling.
Enabling memory oversubscription affects RAM allocation, but CPU Ready Time is strictly related to
CPU contention.
Next Steps to Diagnose & Resolve the Issue
Review Host CPU Utilization:
Navigate to Prism Central → Analysis → CPU Usage per Host.
Identify hosts experiencing high CPU load.
Check VM vCPU Allocation:
Ensure that VMs do not have excessive vCPUs assigned, which can lead to scheduling inefficiencies.
Overprovisioning vCPUs can cause unnecessary contention.
Balance Workload Across Hosts:
Use Nutanix AHV DRS (Dynamic Scheduling) or VMware DRS to redistribute VMs across hosts.
Check if certain hosts are overloaded while others have spare CPU capacity.
Consider Scaling Out the Cluster:
If CPU usage is consistently high, adding more nodes may be required to reduce CPU contention.
Multicloud Infrastructure References & Best Practices
CPU Ready Time Best Practices:
Keep CPU Ready Time below 5%.
Avoid overcommitting vCPUs on heavily loaded hosts.
Monitor Prism Central Runway Metrics to predict future CPU resource needs.
Nutanix AHV CPU Scheduling Optimization:
Ensure proper VM sizing (avoid excessive vCPU allocation).
Balance workloads using Nutanix AHV DRS.
References:
Nutanix Prism Central: Performance Analysis and CPU Metrics
Nutanix Bible: VM Performance and Resource Management
Nutanix KB: Troubleshooting High CPU Ready Time in AHV
Question 4
Refer to Exhibit: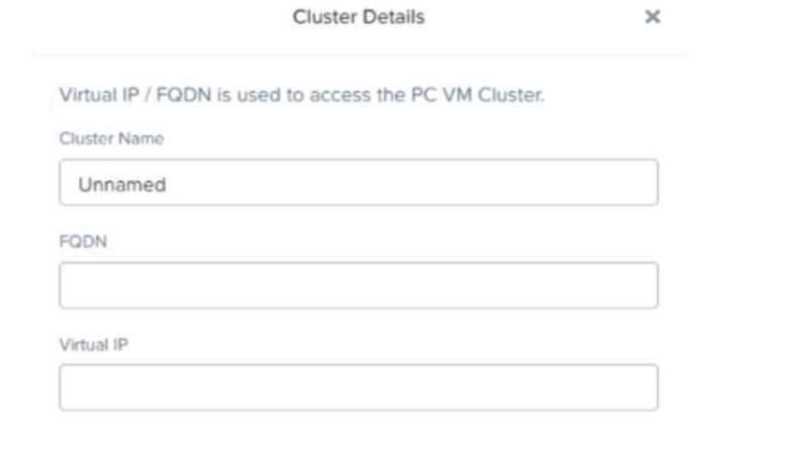
In a scale-out Prism Central deployment, what additional functionality does configuring an FQDN
instead of a Virtual IP provide?
- A. Load balancing
- B. Resiliency
- C. Segmentation
- D. SSL Certificate
Answer:
A
Explanation:
When using FQDN instead of a Virtual IP in a scale-out Prism Central deployment, Nutanix enables
load balancing across multiple Prism Central instances.
Option A (Load balancing) is correct because it ensures that requests are distributed among multiple
Prism Central nodes, improving performance and redundancy.
Option B (Resiliency) is incorrect because resiliency is achieved through HA and replication, not
through FQDN configuration.
Option C (Segmentation) is incorrect because network segmentation is handled at the VLAN or
security policy level.
Option D (SSL Certificate) is incorrect because SSL certificates can be applied regardless of whether
FQDN or Virtual IP is used.
References:
Nutanix Prism Central Deployment Guide
Nutanix Best Practices for Scale-Out Prism Central
Nutanix Support KB: Configuring FQDN for Prism Central
Question 5
Refer to Exhibit: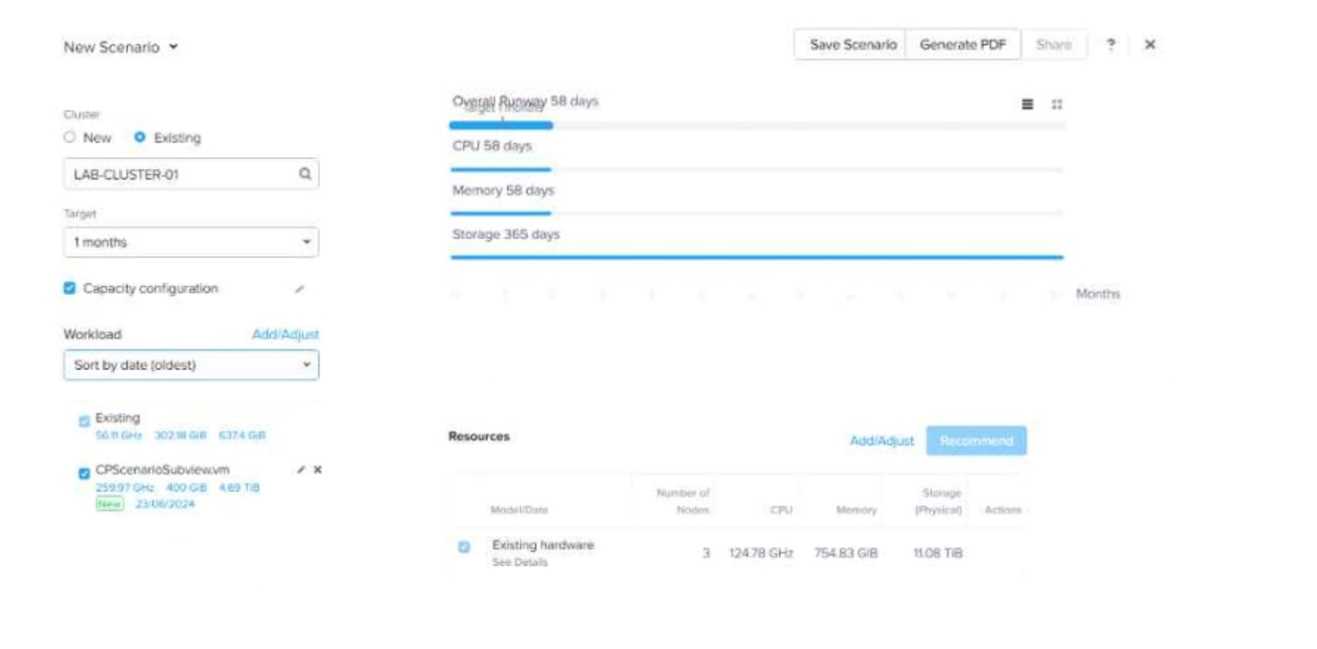
After adding new workloads, why is Overall Runway below 365 days and the scenario still shows the
cluster is in good shape?
- A. Because Storage Runway is still good.
- B. Because new workloads are sustainable.
- C. Because there are recommended resources.
- D. Because the Target is 1 month.
Answer:
B
Explanation:
In Nutanix Capacity Planning, Overall Runway represents how long the cluster can support current
and new workloads before resources are exhausted.
Even if the runway is below 365 days, the system considers the cluster to be in good shape if new
workloads are sustainable (Option B).
Option A is incorrect: Storage runway alone is not the only factor; CPU and memory are equally
important.
Option C is incorrect: The presence of recommended resources does not mean the cluster is in good
shape.
Option D is incorrect: The target of 1 month affects projections but does not explain why the cluster
is in good shape.
References:
Nutanix Prism Central → Capacity Runway and Planning
Nutanix Bible → Workload Placement and Cluster Sizing
Nutanix Support KB → Capacity Planning Best Practices
Question 6
An administrator needs to set up a protection policy in preparation for a Disaster Recovery (DR) test.
What is the first step required to satisfy this task?
- A. Install NGT (Nutanix Guest Tools) on VMs where applications are supported.
- B. Create an Availability Zone between Production and DR.
- C. Convert the source cluster to AHV.
- D. Create a point-in-time snapshot of source VMs.
Answer:
B
Explanation:
For Nutanix Disaster Recovery (DR) protection policies, the first step is to establish a connection
between the Production cluster and the DR site, which is done by creating an Availability Zone (AZ)
(Option B).
Availability Zones (AZs) define remote sites for replication and are a requirement for configuring
protection domains and disaster recovery plans.
Option A (Installing NGT) is not necessary for setting up replication but is useful for application-
consistent snapshots.
Option C (Converting the source cluster to AHV) is not required, as Nutanix supports cross-hypervisor
DR between ESXi and AHV.
Option D (Creating a point-in-time snapshot) is a later step after setting up the Availability Zone and
Protection Policy.
References:
Nutanix Protection Policies and DR Documentation
Nutanix Bible → Disaster Recovery Planning
Nutanix Support KB → Configuring Availability Zones in Prism Central
Question 7
An administrator wants to ensure that VMs can be migrated and restarted on another node in the
event of a single-host failure.
What action should be taken in Prism Element to meet this requirement?
- A. Set Redundancy Factor to 3.
- B. Enable HA Reservation.
- C. Configure a Protection Domain.
- D. Configure an RF1 storage container.
Answer:
B
Explanation:
To ensure VM high availability (HA) in the event of a node failure, the administrator must enable HA
Reservation (Option B) in Prism Element.
High Availability (HA) in Nutanix ensures that VMs restart on another available node if the host they
are running on fails.
Option A (Redundancy Factor 3) affects storage redundancy, not VM failover.
Option C (Protection Domains) is related to disaster recovery (DR), not local HA failover.
Option D (RF1 Storage Container) would reduce fault tolerance and is not recommended for
production environments.
References:
Nutanix Prism Element Guide → Configuring HA Reservation
Nutanix Bible → High Availability (HA) and Failover
Nutanix Support KB → VM Recovery with HA Enabled
Question 8
An administrator started an LCM upgrade of the AHV hosts but realized that the upgrade would
exceed the planned maintenance window.
Which feature should be leveraged to prevent additional updates from occurring?
- A. Cancel the LCM tasks via the Ergon command line (ecli).
- B. Run the lcm_task_cleanup.py script.
- C. Restart Genesis on the cluster to restart the LCM service.
- D. Use the Stop Update feature in LCM.
Answer:
D
Explanation:
When performing a Life Cycle Manager (LCM) upgrade, the recommended way to stop the process is
to use the “Stop Update” feature in LCM (Option D).
Option A (Cancel via Ergon ecli) is not a recommended approach since manually interfering with
running tasks can cause inconsistencies.
Option B (lcm_task_cleanup.py script) is used for post-upgrade cleanup but does not stop ongoing
updates.
Option C (Restarting Genesis) does not stop an LCM upgrade and can cause instability.
References:
Nutanix Life Cycle Manager (LCM) User Guide
Nutanix KB: Best Practices for Stopping and Restarting LCM Tasks
Nutanix Prism Central → LCM Feature Documentation
Question 9
The team leads of a development environment want to limit developer access to a specific set of
VMs.
What is the most efficient way to enable the team leads to directly manage these VMs?
- A. Create a role mapping for each team lead and assign appropriately.
- B. Create a VPC for each team lead and give them VPC Admin.
- C. Create a Project for each team lead and assign access.
- D. Create Security Policies to isolate users.
Answer:
C
Explanation:
The most efficient way to allow team leads to manage a specific set of VMs is by creating a Project
(Option C) in Prism Central and assigning the team leads to that Project.
Nutanix Projects allow administrators to control VM access based on groups and permissions,
ensuring that users only manage VMs assigned to their project.
Option A (Role Mapping) applies more broadly to roles but does not restrict access to specific VM
groups.
Option B (VPC Admin) is related to network segmentation, not VM access control.
Option D (Security Policies) are used for network and firewall rules, not VM access control.
References:
Nutanix Prism Central → Projects and Role-Based Access Control (RBAC)
Nutanix Bible → Multi-Tenancy and Project-Based Access Control
Nutanix KB → Setting Up Role-Based Access Control (RBAC) for Prism Central
Question 10
An administrator needs to configure NTP on Prism Central running on a Hyper-V cluster.
How should the administrator complete this task?
- A. Add an external NTP server.
- B. Add the DNS server IP.
- C. Add a server with a DNS hostname.
- D. Add the IP of the Domain Controller.
Answer:
A
Explanation:
Nutanix requires that all cluster components synchronize time using an external NTP (Network Time
Protocol) server.
Option A (Adding an external NTP server) is correct because Nutanix best practices recommend using
an external time source to prevent clock drift between cluster nodes.
Option B (DNS server IP) is incorrect: A DNS server does not provide NTP services.
Option C (Server with DNS hostname) is incorrect unless the DNS hostname resolves to an NTP
server.
Option D (IP of the Domain Controller) is incorrect because not all domain controllers provide NTP
services unless explicitly configured.
References:
Nutanix Best Practices: NTP Configuration for Hyper-V Clusters
Nutanix KB: Ensuring Proper Time Synchronization Across Cluster Nodes
Nutanix Documentation: Prism Central NTP Settings Configuration
Question 11
Which two entities can be categorized? (Choose two.)
- A. Storage Containers
- B. Alerts
- C. Virtual Machines
- D. ISO Images
Answer:
B, C
Explanation:
In Nutanix Prism Central, categories allow administrators to group and organize entities for
management, automation, and policy enforcement.
Alerts (Option B) can be categorized to group similar system events and create filtering rules.
Virtual Machines (Option C) can be categorized to apply security policies, automation tasks, and
resource allocation rules.
Option A (Storage Containers) cannot be categorized in Prism Central. Storage policies apply at the
container level but are not managed via categories.
Option D (ISO Images) cannot be categorized because ISOs are static objects, not active entities.
References:
Nutanix Prism Central Guide → Working with Categories
Nutanix Bible → Category-Based Management and Security Policies
Nutanix KB → Using Categories for VM Management in Prism Central
Question 12
What feature allows receiving a weekly message about infrastructure performance summary?
- A. Admin Center Life Cycle Manager
- B. Prism Central Syslog
- C. Infrastructure VMs List
- D. Intelligent Operations Reports
Answer:
D
Explanation:
Nutanix Intelligent Operations Reports (Option D) provide weekly summaries of cluster health,
performance, and resource consumption.
These reports include recommendations for optimization, alerts, and forecasted resource usage
trends.
Option A (Admin Center LCM) manages firmware and software upgrades but does not generate
weekly performance reports.
Option B (Prism Central Syslog) is used for logging and event tracking, not performance summaries.
Option C (Infrastructure VMs List) provides a static list of VMs but does not generate periodic reports.
References:
Nutanix Prism Central → Intelligent Operations and Reports
Nutanix Bible → Automated Insights for Cluster Health Monitoring
Nutanix KB → Using Intelligent Operations Reports for Capacity Planning
Question 13
Which storage attributes do Storage Policies manage?
- A. Storage Containers and Volume Groups
- B. Replication Factor and Encryption
- C. Shares and Object Stores
- D. Data Protection and Security
Answer:
B
Explanation:
Storage Policies in Nutanix allow administrators to configure data protection and performance
settings at the storage container level.
Replication Factor (RF) defines the number of copies of data stored across nodes for fault tolerance.
Encryption ensures that data at rest is protected via Nutanix-native encryption methods.
Option A (Storage Containers and Volume Groups) refers to storage organization, not policies.
Option C (Shares and Object Stores) applies to file and object storage services, not VM storage
policies.
Option D (Data Protection and Security) is a broad term but does not define specific policy attributes.
References:
Nutanix Prism Element → Storage Policies and Replication Factor (RF)
Nutanix Bible → Storage Fabric and Data Resiliency
Nutanix KB → Enabling Encryption in Storage Policies
Question 14
Refer to Exhibit: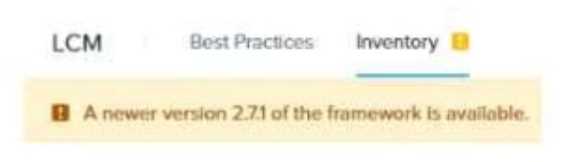
An administrator notices the message shown in the exhibit when navigating to LCM from Prism
Central.
Which action should the administrator take to update LCM to the latest version?
- A. Run an AOS upgrade.
- B. Run an AHV upgrade.
- C. Perform an Inventory Scan.
- D. Download and install the latest LCM version from a CVM.
Answer:
C
Explanation:
When Life Cycle Manager (LCM) reports that a newer framework version is available, the correct
action is to perform an inventory scan (Option C).
Performing an inventory scan updates the available firmware/software versions and allows LCM to
download required updates.
Option A (Run an AOS upgrade) is unrelated to the LCM framework update process.
Option B (Run an AHV upgrade) is a separate component update and does not affect the LCM
framework.
Option D (Download manually from a CVM) is not necessary because LCM updates are automatically
pulled after an inventory scan.
References:
Nutanix LCM User Guide → Updating LCM Framework and Performing Inventory Scans
Nutanix KB → Best Practices for LCM Updates
Nutanix Prism Central → LCM Update Workflow
Question 15
An administrator needs to ensure that a VM is powered on before the rest of the VMs when starting
a host.
Which configuration option allows this behavior?
- A. Recovery Plan
- B. Host Affinity
- C. High Availability
- D. Agent VM
Answer:
D
Explanation:
In Nutanix AHV-based clusters, when you want to ensure that a specific VM (e.g., a critical VM like a
domain controller) is powered on before other VMs during a host startup or failover scenario, you
use the Agent VM configuration setting.
Here’s the exact explanation from the Nutanix ECA course:
“Agent VMs are special VMs that are automatically powered on before other user VMs during host
startup or recovery. This ensures that critical VMs, such as those that provide essential services, are
always available first.”
In contrast:
✅
Recovery Plan (A) — This is used in the context of DR and failover, typically with Nutanix Leap.
✅
Host Affinity (B) — Host affinity rules control placement policies of VMs but not startup priority.
✅
High Availability (C) — HA ensures VMs are restarted on surviving hosts but does not control
startup order.
Therefore, setting the VM as an Agent VM guarantees that it is powered on before the other VMs
during host start-up. Let me know if you’d like steps on how to configure an Agent VM within Prism
Central or Prism Element!