MuleSoft mcpa-level-1 practice test
MuleSoft Certified Platform Architect - Level 1
Question 1
What API policy would LEAST likely be applied to a Process API?
- A. Custom circuit breaker
- B. Client ID enforcement
- C. Rate limiting
- D. JSON threat protection
Answer:
D
Explanation:
Correct Answer: JSON threat protection
*****************************************
Fact: Technically, there are no restrictions on what policy can be applied in what layer. Any policy can
be applied on any layer API. However, context should also be considered properly before blindly
applying the policies on APIs.
That is why, this question asked for a policy that would LEAST likely be applied to a Process API.
From the given options:
>> All policies except "JSON threat protection" can be applied without hesitation to the APIs in
Process tier.
>> JSON threat protection policy ideally fits for experience APIs to prevent suspicious JSON payload
coming from external API clients. This covers more of a security aspect by trying to avoid possibly
malicious and harmful JSON payloads from external clients calling experience APIs.
As external API clients are NEVER allowed to call Process APIs directly and also these kind of
malicious and harmful JSON payloads are always stopped at experience API layer only using this
policy, it is LEAST LIKELY that this same policy is again applied on Process Layer API.
Reference:
https://docs.mulesoft.com/api-manager/2.x/policy-mule3-provided-policies
Question 2
What is a key performance indicator (KPI) that measures the success of a typical C4E that is
immediately apparent in responses from the Anypoint Platform APIs?
- A. The number of production outage incidents reported in the last 24 hours
- B. The number of API implementations that have a publicly accessible HTTP endpoint and are being managed by Anypoint Platform
- C. The fraction of API implementations deployed manually relative to those deployed using a CI/CD tool
- D. The number of API specifications in RAML or OAS format published to Anypoint Exchange
Answer:
D
Explanation:
Correct Answer: The number of API specifications in RAML or OAS format published to Anypoint
Exchange
*****************************************
>> The success of C4E always depends on their contribution to the number of reusable assets that
they have helped to build and publish to Anypoint Exchange.
>> It is NOT due to any factors w.r.t # of outages, Manual vs CI/CD deployments or Publicly accessible
HTTP endpoints
>> Anypoint Platform APIs helps us to quickly run and get the number of published RAML/OAS assets
to Anypoint Exchange. This clearly depicts how successful a C4E team is based on number of
returned assets in the response.
Reference:
https://help.mulesoft.com/s/question/0D52T00004mXSTUSA4/how-should-a-company-
measure-c4e-success
Question 3
An organization is implementing a Quote of the Day API that caches today's quote.
What scenario can use the GoudHub Object Store via the Object Store connector to persist the
cache's state?
- A. When there are three CloudHub deployments of the API implementation to three separate CloudHub regions that must share the cache state
- B. When there are two CloudHub deployments of the API implementation by two Anypoint Platform business groups to the same CloudHub region that must share the cache state
- C. When there is one deployment of the API implementation to CloudHub and anottV deployment to a customer-hosted Mule runtime that must share the cache state
- D. When there is one CloudHub deployment of the API implementation to three CloudHub workers that must share the cache state
Answer:
D
Explanation:
Correct Answer: When there is one CloudHub deployment of the API implementation to three
CloudHub workers that must share the cache state.
*****************************************
Key details in the scenario:
>> Use the CloudHub Object Store via the Object Store connector
Considering above details:
>> CloudHub Object Stores have one-to-one relationship with CloudHub Mule Applications.
>> We CANNOT use an application's CloudHub Object Store to be shared among multiple Mule
applications running in different Regions or Business Groups or Customer-hosted Mule Runtimes by
using Object Store connector.
>> If it is really necessary and very badly needed, then Anypoint Platform supports a way by allowing
access to CloudHub Object Store of another application using Object Store REST API. But NOT using
Object Store connector.
So, the only scenario where we can use the CloudHub Object Store via the Object Store connector to
persist the cache’s state is when there is one CloudHub deployment of the API implementation to
multiple CloudHub workers that must share the cache state.
Question 4
What condition requires using a CloudHub Dedicated Load Balancer?
- A. When cross-region load balancing is required between separate deployments of the same Mule application
- B. When custom DNS names are required for API implementations deployed to customer-hosted Mule runtimes
- C. When API invocations across multiple CloudHub workers must be load balanced
- D. When server-side load-balanced TLS mutual authentication is required between API implementations and API clients
Answer:
D
Explanation:
Correct Answer: When server-side load-balanced TLS mutual authentication is required between API
implementations and API clients
*****************************************
Fact/ Memory Tip: Although there are many benefits of CloudHub Dedicated Load balancer, TWO
important things that should come to ones mind for considering it are:
>> Having URL endpoints with Custom DNS names on CloudHub deployed apps
>> Configuring custom certificates for both HTTPS and Two-way (Mutual) authentication.
Coming to the options provided for this
>> We
CANNOT use DLB to perform cross-region load balancing between separate deployments of the same
Mule application.
>> We can have mapping rules to have more than one DLB URL pointing to same Mule app. But
vicevera (More than one Mule app having same DLB URL) is NOT POSSIBLE
>> It is true that DLB helps to setup custom DNS names for Cloudhub deployed Mule apps but NOT
true for apps deployed to Customer-hosted Mule Runtimes.
>> It is true to that we can load balance API invocations across multiple CloudHub workers using DLB
but it is NOT A MUST. We can achieve the same (load balancing) using SLB (Shared Load Balancer)
too. We DO NOT necessarily require DLB for achieve it.
So the only right option that fits the scenario and requires us to use DLB is when TLS mutual
authentication is required between API implementations and API clients.
Reference:
https://docs.mulesoft.com/runtime-manager/cloudhub-dedicated-load-balancer
Question 5
What do the API invocation metrics provided by Anypoint Platform provide?
- A. ROI metrics from APIs that can be directly shared with business users
- B. Measurements of the effectiveness of the application network based on the level of reuse
- C. Data on past API invocations to help identify anomalies and usage patterns across various APIs
- D. Proactive identification of likely future policy violations that exceed a given threat threshold
Answer:
C
Explanation:
Correct Answer: Data on past API invocations to help identify anomalies and usage patterns across
various APIs
*****************************************
API Invocation metrics provided by Anypoint Platform:
>> Does NOT provide any Return Of Investment (ROI) related information. So the option suggesting it
is OUT.
>> Does NOT provide any information w.r.t how APIs are reused, whether there is effective usage of
APIs or not etc...
>> Does NOT prodive any prediction information as such to help us proactively identify any future
policy violations.
So, the kind of data/information we can get from such metrics is on past API invocations to help
identify anomalies and usage patterns across various APIs.
Reference:
https://usermanual.wiki/Document/APAAppNetstudentManual02may2018.991784750.pdf
Question 6
What is true about the technology architecture of Anypoint VPCs?
- A. The private IP address range of an Anypoint VPC is automatically chosen by CloudHub
- B. Traffic between Mule applications deployed to an Anypoint VPC and on-premises systems can stay within a private network
- C. Each CloudHub environment requires a separate Anypoint VPC
- D. VPC peering can be used to link the underlying AWS VPC to an on-premises (non AWS) private network
Answer:
B
Explanation:
Correct Answer: Traffic between Mule applications deployed to an Anypoint VPC and on-premises
systems can stay within a private network
*****************************************
>> The private IP address range of an Anypoint VPC is NOT automatically chosen by CloudHub. It is
chosen by us at the time of creating VPC using thr CIDR blocks.
CIDR Block: The size of the Anypoint VPC in Classless Inter-Domain Routing (CIDR) notation.
For example, if you set it to 10.111.0.0/24, the Anypoint VPC is granted 256 IP addresses from
10.111.0.0 to 10.111.0.255.
Ideally, the CIDR Blocks you choose for the Anypoint VPC come from a private IP space, and should
not overlap with any other Anypoint VPC’s CIDR Blocks, or any CIDR Blocks in use in your corporate
network.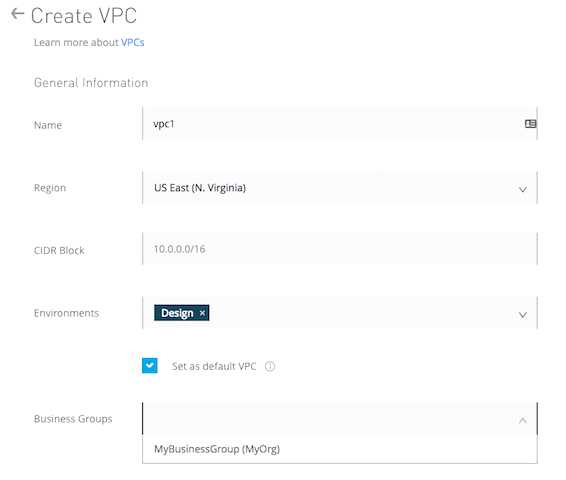
that each CloudHub environment requires a separate Anypoint VPC. Once an Anypoint VPC is
created, we can choose a same VPC by multiple environments. However, it is generally a best and
recommended practice to always have seperate Anypoint VPCs for Non-Prod and Prod environments.
>> We use Anypoint VPN to link the underlying AWS VPC to an on-premises (non AWS) private
network. NOT VPC Peering.
Reference:
https://docs.mulesoft.com/runtime-manager/vpn-about
Only true statement in the given choices is that the traffic between Mule applications deployed to an
Anypoint VPC and on-premises systems can stay within a private network.
https://docs.mulesoft.com/runtime-manager/vpc-connectivity-methods-concept
Question 7
An API implementation is deployed on a single worker on CloudHub and invoked by external API
clients (outside of CloudHub). How can an alert be set up that is guaranteed to trigger AS SOON AS
that API implementation stops responding to API invocations?
- A. Implement a heartbeat/health check within the API and invoke it from outside the Anypoint Platform and alert when the heartbeat does not respond
- B. Configure a "worker not responding" alert in Anypoint Runtime Manager
- C. Handle API invocation exceptions within the calling API client and raise an alert from that API client when the API Is unavailable
- D. Create an alert for when the API receives no requests within a specified time period
Answer:
B
Explanation:
Correct Answer: Configure a “Worker not responding” alert in Anypoint Runtime Manager.
*****************************************
>> All the options eventually helps to generate the alert required when the application stops
responding.
>> However, handling exceptions within calling API and then raising alert from API client is
inappropriate and silly. There could be many API clients invoking the API implementation and it is not
ideal to have this setup consistently in all of them. Not a realistic way to do.
>> Implementing a health check/ heartbeat with in the API and calling from outside to detmine the
health sounds OK but needs extra setup for it and same time there are very good chances of
generating false alarms when there are any intermittent network issues between external tool
calling the health check API on API implementation. The API implementation itself may not have any
issues but due to some other factors some false alarms may go out.
>> Creating an alert in API Manager when the API receives no requests within a specified time period
would actually generate realistic alerts but even here some false alarms may go out when there are
genuinely no requests from API clients.
The best and right way to achieve this requirement is to setup an alert on Runtime Manager with a
condition "Worker not responding". This would generate an alert AS SOON AS the workers become
unresponsive.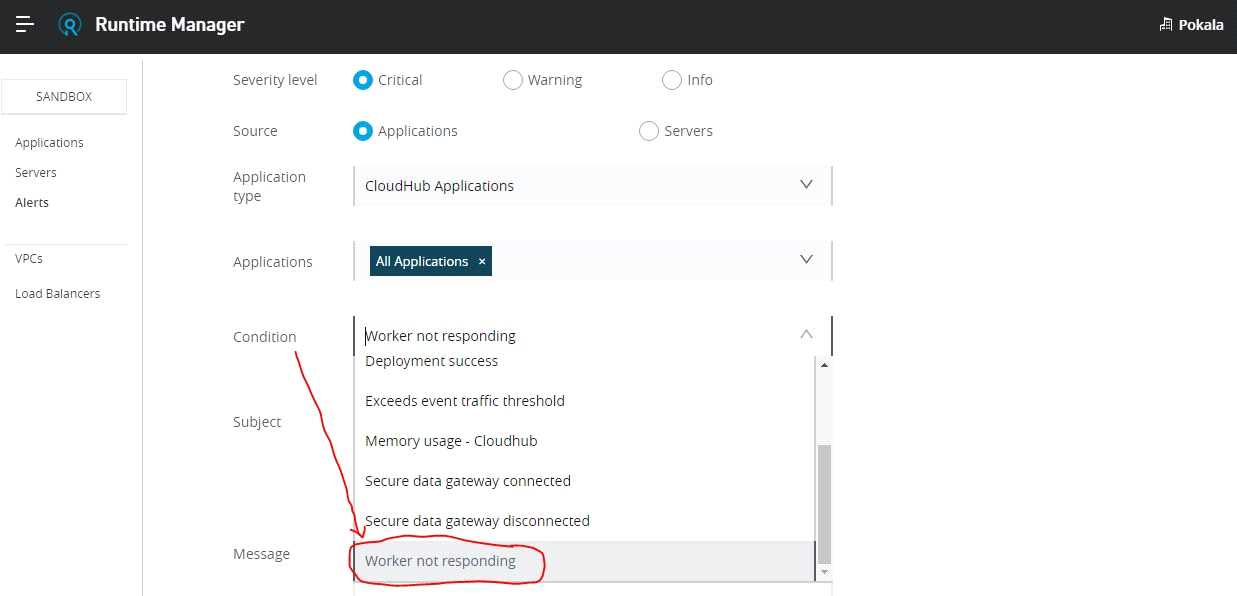
Question 8
The implementation of a Process API must change.
What is a valid approach that minimizes the impact of this change on API clients?
- A. Update the RAML definition of the current Process API and notify API client developers by sending them links to the updated RAML definition
- B. Postpone changes until API consumers acknowledge they are ready to migrate to a new Process API or API version
- C. Implement required changes to the Process API implementation so that whenever possible, the Process API's RAML definition remains unchanged
- D. Implement the Process API changes in a new API implementation, and have the old API implementation return an HTTP status code 301 - Moved Permanently to inform API clients they should be calling the new API implementation
Answer:
C
Explanation:
Correct Answer: Implement required changes to the Process API implementation so that, whenever
possible, the Process API’s RAML definition remains unchanged.
*****************************************
Key requirement in the question is:
>> Approach that minimizes the impact of this change on API clients
Based on above:
>> Updating the RAML definition would possibly impact the API clients if the changes require any
thing mandatory from client side. So, one should try to avoid doing that until really necessary.
>> Implementing the changes as a completely different API and then redirectly the clients with 3xx
status code is really upsetting design and heavily impacts the API clients.
>> Organisations and IT cannot simply postpone the changes required until all API consumers
acknowledge they are ready to migrate to a new Process API or API version. This is unrealistic and
not possible.
The best way to handle the changes always is to implement required changes to the API
implementations so that, whenever possible, the API’s RAML definition remains unchanged.
Question 9
Refer to the exhibit. An organization needs to enable access to their customer data from both a
mobile app and a web application, which each need access to common fields as well as certain
unique fields.
The data is available partially in a database and partially in a 3rd-party CRM system.
What APIs should be created to best fit these design requirements?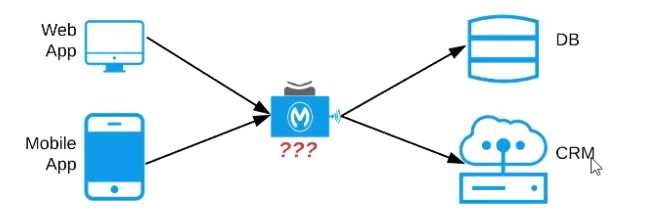
A) A Process API that contains the data required by both the web and mobile apps, allowing these
applications to invoke it directly and access the data they need thereby providing the flexibility to
add more fields in the future without needing API changes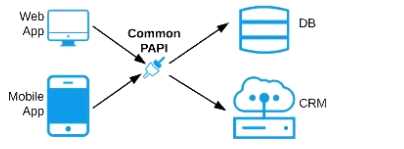
B) One set of APIs (Experience API, Process API, and System API) for the web app, and another set for
the mobile app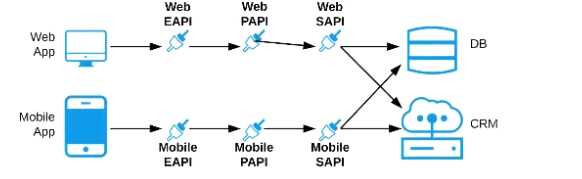
C) Separate Experience APIs for the mobile and web app, but a common Process API that invokes
separate System APIs created for the database and CRM system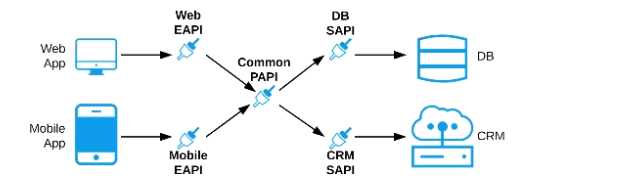
D) A common Experience API used by both the web and mobile apps, but separate Process APIs for
the web and mobile apps that interact with the database and the CRM System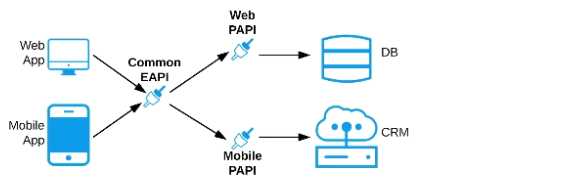
- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer:
C
Explanation:
Correct Answer: Separate Experience APIs for the mobile and web app, but a common Process API
that invokes separate System APIs created for the database and CRM system
*****************************************
As per MuleSoft's API-led connectivity:
>> Experience APIs should be built as per each consumer needs and their experience.
>> Process APIs should contain all the orchestration logic to achieve the business functionality.
>> System APIs should be built for each backend system to unlock their data.
Reference:
https://blogs.mulesoft.com/dev/api-dev/what-is-api-led-connectivity/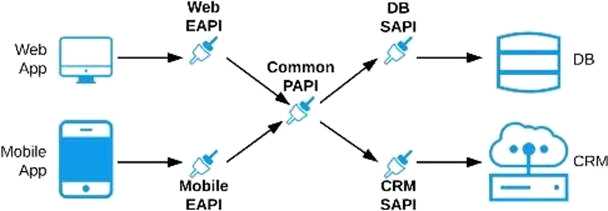
Question 10
Refer to the exhibit.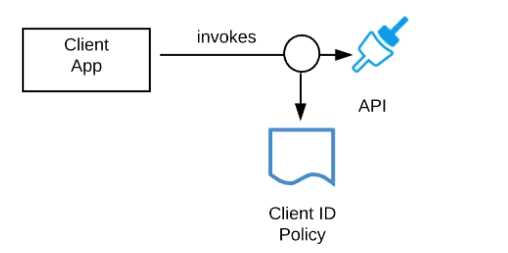
A developer is building a client application to invoke an API deployed to the STAGING environment
that is governed by a client ID enforcement policy.
What is required to successfully invoke the API?
- A. The client ID and secret for the Anypoint Platform account owning the API in the STAGING environment
- B. The client ID and secret for the Anypoint Platform account's STAGING environment
- C. The client ID and secret obtained from Anypoint Exchange for the API instance in the STAGING environment
- D. A valid OAuth token obtained from Anypoint Platform and its associated client ID and secret
Answer:
C
Explanation:
Correct Answer: The client ID and secret obtained from Anypoint Exchange for the API instance in the
STAGING environment
*****************************************
>> We CANNOT use the client ID and secret of Anypoint Platform account or any individual
environments for accessing the APIs
>> As the type of policy that is enforced on the API in question is "Client ID Enforcment Policy",
OAuth token based access won't work.
Right way to access the API is to use the client ID and secret obtained from Anypoint Exchange for
the API instance in a particular environment we want to work on.
References:
Managing API instance Contracts on API Manager
https://docs.mulesoft.com/api-manager/1.x/request-access-to-api-task
https://docs.mulesoft.com/exchange/to-request-access
https://docs.mulesoft.com/api-manager/2.x/policy-mule3-client-id-based-policies
Question 11
In an organization, the InfoSec team is investigating Anypoint Platform related data traffic.
From where does most of the data available to Anypoint Platform for monitoring and alerting
originate?
- A. From the Mule runtime or the API implementation, depending on the deployment model
- B. From various components of Anypoint Platform, such as the Shared Load Balancer, VPC, and Mule runtimes
- C. From the Mule runtime or the API Manager, depending on the type of data
- D. From the Mule runtime irrespective of the deployment model
Answer:
D
Explanation:
Correct Answer: From the Mule runtime irrespective of the deployment model
*****************************************
>> Monitoring and Alerting metrics are always originated from Mule Runtimes irrespective of the
deployment model.
>> It may seems that some metrics (Runtime Manager) are originated from Mule Runtime and some
are (API Invocations/ API Analytics) from API Manager. However, this is realistically NOT TRUE. The
reason is, API manager is just a management tool for API instances but all policies upon applying on
APIs eventually gets executed on Mule Runtimes only (Either Embedded or API Proxy).
>> Similarly all API Implementations also run on Mule Runtimes.
So, most of the day required for monitoring and alerts are originated fron Mule Runtimes only
irrespective of whether the deployment model is MuleSoft-hosted or Customer-hosted or Hybrid.
Question 12
When designing an upstream API and its implementation, the development team has been advised
to NOT set timeouts when invoking a downstream API, because that downstream API has no SLA that
can be relied upon. This is the only downstream API dependency of that upstream API.
Assume the downstream API runs uninterrupted without crashing. What is the impact of this advice?
- A. An SLA for the upstream API CANNOT be provided
- B. The invocation of the downstream API will run to completion without timing out
- C. A default timeout of 500 ms will automatically be applied by the Mule runtime in which the upstream API implementation executes
- D. A toad-dependent timeout of less than 1000 ms will be applied by the Mule runtime in which the downstream API implementation executes
Answer:
A
Explanation:
Correct Answer: An SLA for the upstream API CANNOT be provided.
*****************************************
>> First thing first, the default HTTP response timeout for HTTP connector is 10000 ms (10 seconds).
NOT 500 ms.
>> Mule runtime does NOT apply any such "load-dependent" timeouts. There is no such behavior
currently in Mule.
>> As there is default 10000 ms time out for HTTP connector, we CANNOT always guarantee that the
invocation of the downstream API will run to completion without timing out due to its unreliable SLA
times. If the response time crosses 10 seconds then the request may time out.
The main impact due to this is that a proper SLA for the upstream API CANNOT be provided.
Reference:
https://docs.mulesoft.com/http-connector/1.5/http-documentation#parameters-3
Question 13
What best explains the use of auto-discovery in API implementations?
- A. It makes API Manager aware of API implementations and hence enables it to enforce policies
- B. It enables Anypoint Studio to discover API definitions configured in Anypoint Platform
- C. It enables Anypoint Exchange to discover assets and makes them available for reuse
- D. It enables Anypoint Analytics to gain insight into the usage of APIs
Answer:
A
Explanation:
Correct Answer: It makes API Manager aware of API implementations and hence enables it to
enforce policies.
*****************************************
>> API Autodiscovery is a mechanism that manages an API from API Manager by pairing the
deployed application to an API created on the platform.
>> API Management includes tracking, enforcing policies if you apply any, and reporting API
analytics.
>> Critical to the Autodiscovery process is identifying the API by providing the API name and version.
References:
https://docs.mulesoft.com/api-manager/2.x/api-auto-discovery-new-concept
https://docs.mulesoft.com/api-manager/1.x/api-auto-discovery
https://docs.mulesoft.com/api-manager/2.x/api-auto-discovery-new-concept
Question 14
What should be ensured before sharing an API through a public Anypoint Exchange portal?
- A. The visibility level of the API instances of that API that need to be publicly accessible should be set to public visibility
- B. The users needing access to the API should be added to the appropriate role in Anypoint Platform
- C. The API should be functional with at least an initial implementation deployed and accessible for users to interact with
- D. The API should be secured using one of the supported authentication/authorization mechanisms to ensure that data is not compromised
Answer:
A
Explanation: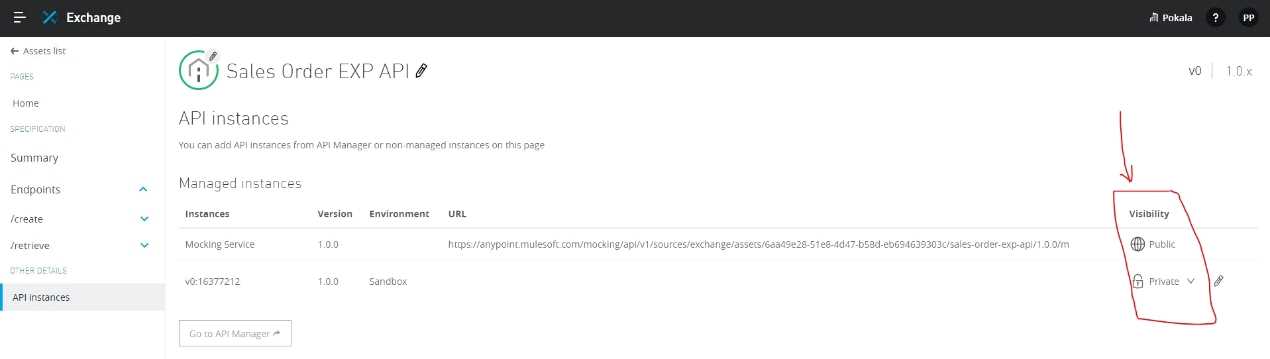
Correct Answer: The visibility level of the API instances of that API that need to be publicly accessible
should be set to public visibility.
*****************************************
Reference:
https://docs.mulesoft.com/exchange/to-share-api-asset-to-portal
https://docs.mulesoft.com/exchange/to-share-api-asset-to-portal
Question 15
Refer to the exhibit.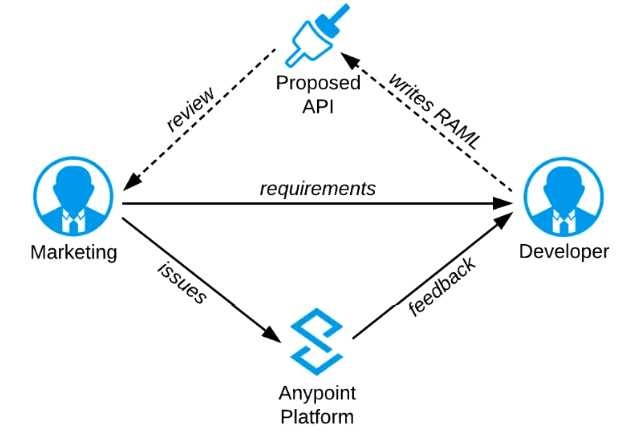
A RAML definition has been proposed for a new Promotions Process API, and has been published to
Anypoint Exchange.
The Marketing Department, who will be an important consumer of the Promotions API, has
important requirements and expectations that must be met.
What is the most effective way to use Anypoint Platform features to involve the Marketing
Department in this early API design phase?
A) Ask the Marketing Department to interact with a mocking implementation of the API using the
automatically generated API Console
B) Organize a design workshop with the DBAs of the Marketing Department in which the database
schema of the Marketing IT systems is translated into RAML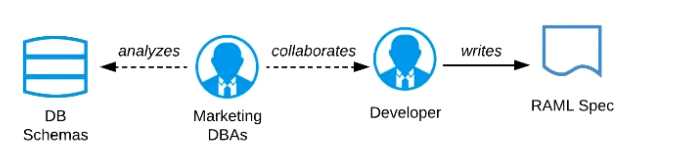
C) Use Anypoint Studio to Implement the API as a Mule application, then deploy that API
implementation to CloudHub and ask the Marketing Department to interact with it
D) Export an integration test suite from API designer and have the Marketing Department execute
the tests In that suite to ensure they pass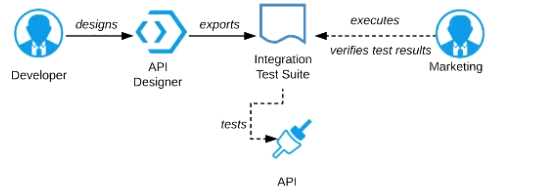
- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer:
A
Explanation:
Correct Answer: Ask the Marketing Department to interact with a mocking implementation of the
API using the automatically generated API Console.
*****************************************
As per MuleSoft's IT Operating Model:
>> API consumers need NOT wait until the full API implementation is ready.
>> NO technical test-suites needs to be shared with end users to interact with APIs.
>> Anypoint Platform offers a mocking capability on all the published API specifications to Anypoint
Exchange which also will be rich in documentation covering all details of API functionalities and
working nature.
>> No needs of arranging days of workshops with end users for feedback.
API consumers can use Anypoint Exchange features on the platform and interact with the API using
its mocking feature. The feedback can be shared quickly on the same to incorporate any changes.