microsoft dp-420 practice test
designing and implementing cloud-native applications using microsoft azure cosmos db
Question 1
You plan to create an Azure Cosmos DB Core (SQL) API account that will use customer-managed keys stored in Azure Key Vault.
You need to configure an access policy in Key Vault to allow Azure Cosmos DB access to the keys.
Which three permissions should you enable in the access policy? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
- A. Wrap Key
- B. Get
- C. List
- D. Update
- E. Sign
- F. Verify
- G. Unwrap Key
Answer:
abg
To Configure customer-managed keys for your Azure Cosmos account with Azure Key Vault:
Add an access policy to your Azure Key Vault instance:
1. From the Azure portal, go to the Azure Key Vault instance that you plan to use to host your encryption keys. Select Access Policies from the left menu:
2. Select + Add Access Policy.
3. Under the Key permissions drop-down menu, select Get, Unwrap Key, and Wrap Key permissions: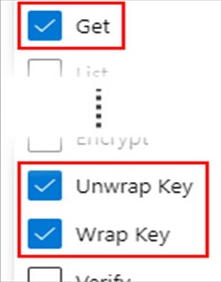
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/how-to-setup-cmk
Question 2
HOTSPOT
You plan to create an Azure Cosmos DB database named db1 that will contain two containers. One of the containers will contain blog posts, and the other will contain users. Each item in the blog post container will include:
A single blog post
All the comments associated to the blog post
The names of the users who created the blog post and added the comments
You need to design a solution to update usernames in the user container without causing data integrity issues. The solution must minimize administrative and development effort.
What should you include in the solution? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:

Question 3
HOTSPOT You have three containers in an Azure Cosmos DB Core (SQL) API account as shown in the following table.
You have the following Azure functions:
A function named Fn1 that reads the change feed of cn1
A function named Fn2 that reads the change feed of cn2
A function named Fn3 that reads the change feed of cn3
You perform the following actions:
Delete an item named item1 from cn1.
Update an item named item2 in cn2.
For an item named item3 in cn3, update the item time to live to 3,600 seconds.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Box 1: No -
Azure Cosmos DB's change feed is a great choice as a central data store in event sourcing architectures where all data ingestion is modeled as writes (no updates or deletes).
Note: The change feed does not capture deletes. If you delete an item from your container, it is also removed from the change feed. The most common method of handling this is adding a soft marker on the items that are being deleted. You can add a property called deleted and set it to true at the time of deletion. This document update will show up in the change feed. You can set a TTL on this item so that it can be automatically deleted later.
Box 2: No -
The _etag format is internal and you should not take dependency on it, because it can change anytime.
Box 3: Yes -
Change feed support in Azure Cosmos DB works by listening to an Azure Cosmos container for any changes.
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/sql/change-feed-design-patterns https://docs.microsoft.com/en-us/azure/cosmos-db/change-feed
Question 4
You plan to create an Azure Cosmos DB account that will use the NoSQL API.
You need to create a grouping strategy for items that will be stored in the account. The solution must ensure that write and read operations on the items can be performed within the same transaction.
What should you use to group the items?
- A. logical partitions
- B. physical partitions
- C. databases
- D. containers
Answer:
a
Question 5
HOTSPOT You configure Azure Cognitive Search to index a container in an Azure Cosmos DB Core (SQL) API account as shown in the following exhibit.
Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Box 1: country -
The country field is filterable.
Note: filterable: Indicates whether to enable the field to be referenced in $filter queries. Filterable differs from searchable in how strings are handled. Fields of type
Edm.String or Collection(Edm.String) that are filterable do not undergo lexical analysis, so comparisons are for exact matches only.
Box 2: name -
The name field is not Retrievable.
Retrievable: Indicates whether the field can be returned in a search result. Set this attribute to false if you want to use a field (for example, margin) as a filter, sorting, or scoring mechanism but do not want the field to be visible to the end user.
Note: searchable: Indicates whether the field is full-text searchable and can be referenced in search queries.
Reference:
https://docs.microsoft.com/en-us/rest/api/searchservice/create-index
Question 6
DRAG DROP You have an app that stores data in an Azure Cosmos DB Core (SQL) API account The app performs queries that return large result sets.
You need to return a complete result set to the app by using pagination. Each page of results must return 80 items.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
Select and Place: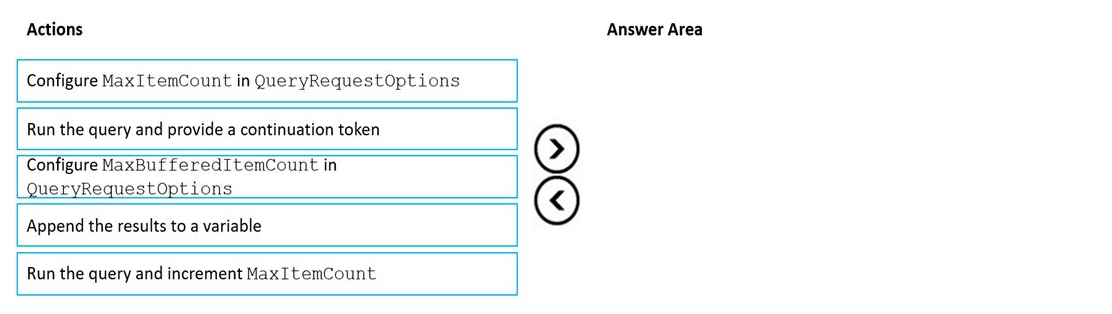
Answer:

Step 1: Configure the MaxItemCount in QueryRequestOptions
You can specify the maximum number of items returned by a query by setting the MaxItemCount. The MaxItemCount is specified per request and tells the query engine to return that number of items or fewer.
Box 2: Run the query and provide a continuation token
In the .NET SDK and Java SDK you can optionally use continuation tokens as a bookmark for your query's progress. Azure Cosmos DB query executions are stateless at the server side and can be resumed at any time using the continuation token.
If the query returns a continuation token, then there are additional query results.
Step 3: Append the results to a variable
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/sql/sql-query-pagination
Question 7
You have an Azure Cosmos DB for NoSQL account.
You configure the diagnostic settings to send all log information to a Log Analytics workspace.
You need to identify when the provisioned request units per second (RU/s) for resources within the account were modified.
You write the following query.
AzureDiagnostics | where Category == ControlPlaneRequests
What should you include in the query?
- A. | where OperationName startswith "RegionAddComplete"
- B. | where OperationName startswith "SqlContainersCreate"
- C. | where OperationName startswith "MongoCollectionsThroughputUpdate"
- D. | where OperationName startswith "SqlContainersThroughputUpdate"
Answer:
a
Question 8
HOTSPOT
You have the Azure Cosmos DB for NoSQL containers shown in the following table.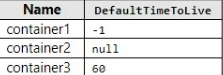
You have the items shown in the following table.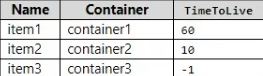
When will each item expire? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.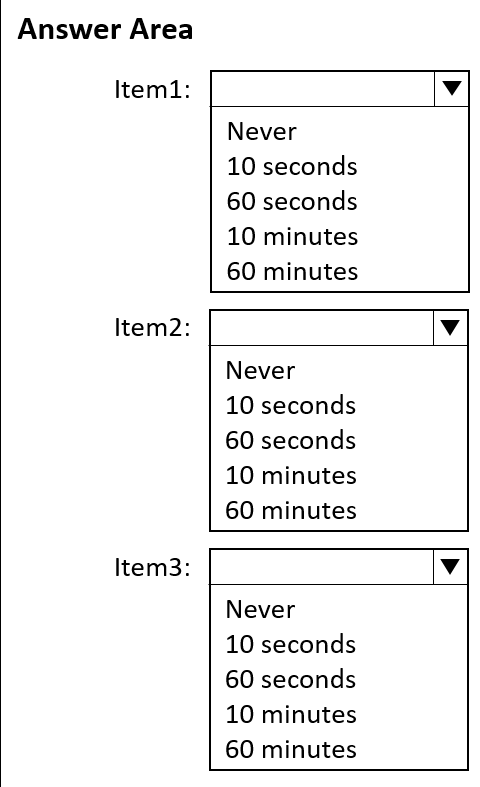
Answer:
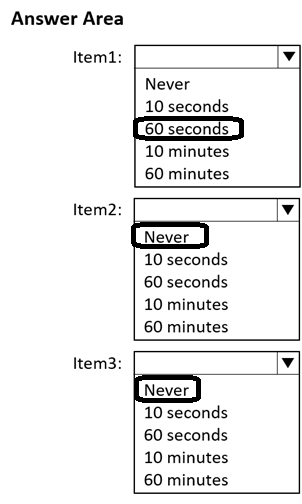
Question 9
HOTSPOT You have a container named container1 in an Azure Cosmos DB Core (SQL) API account named account1.
You configure container1 to use Always Encrypted by using an encryption policy as shown in the C# and the Java exhibits. (Click the C# tab to view the encryption policy in C#.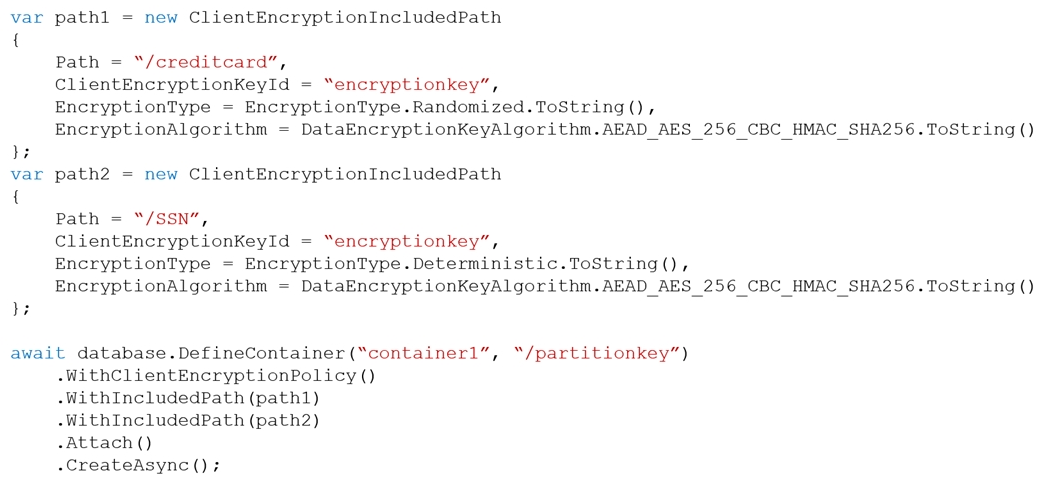
Click the Java tab to see the encryption policy in Java.)
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:
Answer:

Box 1: No -
The creditcard property uses randomized encryption.
Randomized encryption is more secure, but prevents queries from filtering on encrypted properties.
Box 2: Yes -
The SSN property uses deterministic encryption.
Using deterministic encryption allows queries to perform equality filters on encrypted properties.
Box 3: Yes -
Reading documents when only a subset of properties can be decrypted.
In situations where the client does not have access to all the CMK used to encrypt properties, only a subset of properties can be decrypted when data is read back. For example, if property1 was encrypted with key1 and property2 was encrypted with key2, a client application that only has access to key1 can still read data, but not property2. In such a case, you must read your data through SQL queries and project away the properties that the client can't decrypt: SELECT c.property1, c.property3 FROM c.
Reference:
https://docs.microsoft.com/en-us/azure/cosmos-db/how-to-always-encrypted
Question 10
HOTSPOT
You have an Azure Cosmos DB for NoSQL account.
You plan to create a container named container1. The container1 container will store items that include two properties named name and age.
The most commonly executed queries will query container1 for a specific name. The following is a sample of the query.
You need to define an opt-in indexing policy for container1. The solution must meet the following requirements:
Minimize the number of request units consumed by the queries.
Ensure that the _etag property is excluded from indexing.
How should you define the indexing policy? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Answer:
