HP hpe7-j02 practice test
Advanced HPE Storage Integrator Solutions Written Exam
Question 1
Select the scenario where implementing FCoE would be an appropriate solution.
- A. A large enterprise data center with existing Fibre Channel SANs is looking to reduce hardware complexity and costs by consolidating their storage and production networks onto a single infrastructure, while maintaining high performance for mission-critical applications.
- B. A corporation needs to replicate data between data centers in different countries. The data must be synchronized in real-time across a WAN, and the solution must tolerate variable network conditions with minimal impact on performance.
- C. A company with data centers in different states wants to establish a unified SAN infrastructure. The goal is to centralize storage management across all sites, using a single protocol that can efficiently handle high-latency, long-distance connections between data centers.
- D. A tech startup is developing an AI-based application that relies heavily on machine learning models. The team needs a solution that allows them to access and process large datasets in the cloud.
Answer:
A
Explanation:
Detailed Explanatio n:
Rationale for Correct Answe r:
Option A is correct because Fibre Channel over Ethernet (FCoE) is designed for large enterprise
environments that already have Fibre Channel (FC) infrastructures but want to simplify cabling and
reduce hardware by converging LAN and SAN traffic over a single Ethernet fabric. FCoE retains the
efficiency, low latency, and reliability of Fibre Channel while leveraging Ethernet to minimize physical
infrastructure costs. This aligns with HPE’s best practices for environments using HPE Alletra
9000/Primera or HPE Nimble arrays connected to converged networks where cost reduction and high
performance are equally important.
Analysis of Incorrect Options (Distractors):
B: Real-time replication across WANs requires protocols like HPE 3PAR/Alletra Remote Copy,
asynchronous/synchronous replication, or HPE Peer Persistence. FCoE is not suited for high-latency
WANs because it is a LAN protocol designed for short distances within a data center.
C: For inter-data center SAN unification, FCIP (Fibre Channel over IP) or iSCSI are more suitable. FCoE
does not handle long-distance high-latency links effectively.
D: A startup building AI applications with cloud workloads typically benefits from object storage (HPE
Scality RING, HPE GreenLake for File and Object) or direct cloud-native APIs (S3/Blob). FCoE is
irrelevant in this use case since it is on-prem and infrastructure-focused.
Key Concept:
The question is testing knowledge of FCoE and its appropriate deployment scenarios — specifically,
its role in consolidating storage and network traffic inside enterprise data centers while preserving
Fibre Channel protocol advantages.
Reference:
HPE Storage Networking Best Practices Guide
HPE Primera/Alletra 9000 Technical White Paper
Fibre Channel over Ethernet Standards Overview (IEEE 802.1Qbb, 802.1Qaz)
Question 2
Your customer has deployed an HPE Alletra MP B10000 array in its virtualized environment. Data
protection follows 3-2-1 best practices, with snapshots on the array, Veeam v12 backups, and storage
on an external HPE StoreOnce appliance. Despite this, a ransomware attack made data recovery
impossible.
Your customer asks how to enhance data protection with immutability and application consistency.
What is a possible solution using HPE Virtual Lock technology?
- A. Enable Virtual Lock for each backup job inside Veeam v12
- B. Enable Virtual Lock on the VMware datastores in VMware vCenter
- C. Enable Virtual Lock on the HPE StoreOnce Catalyst stores
- D. Enable Virtual Lock on the HPE Alletra storage array
Answer:
C
Explanation:
Detailed Explanatio n:
Rationale for Correct Answe r:
Option C is correct because HPE StoreOnce Virtual Lock technology provides immutability at the
Catalyst store level, preventing backup data from being deleted or modified for a defined retention
period. This ensures ransomware or malicious actors cannot encrypt, alter, or delete the protected
backups, aligning with modern data protection requirements for immutability and compliance. In
integration with Veeam v12, backups stored on StoreOnce Catalyst stores can be locked, creating an
additional immutability layer beyond application-consistent snapshots.
Analysis of Incorrect Options (Distractors):
A: Virtual Lock is not a Veeam feature. While Veeam v12 supports immutability on certain storage
backends (object lock-enabled S3, hardened Linux repositories), HPE Virtual Lock is specific to
StoreOnce Catalyst stores, not Veeam job settings.
B: VMware vCenter datastores do not have a native immutability feature. Snapshots in vCenter can
be deleted or corrupted during ransomware events, making this option incorrect.
D: HPE Alletra arrays support application-consistent snapshots and replication, but they do not
provide the immutability guarantee that StoreOnce Virtual Lock enforces. Array-level snapshots can
still be deleted if admin credentials are compromised.
Key Concept:
This question targets knowledge of HPE StoreOnce Virtual Lock — a feature designed to enforce
immutability on Catalyst backup stores, making backup data resistant to deletion or alteration during
ransomware or insider attacks.
Reference:
HPE StoreOnce Systems Technical White Paper
HPE StoreOnce and Veeam Integration Best Practices
HPE Data Protection Solutions for Ransomware Resilience Guide
Question 3
You are troubleshooting a storage environment using HPE Alletra Storage MP B10000 in a Peer
Persistence configuration. A customer reports high latency when accessing data from applications.
When reviewing the MPIO path status on the host, what should be the path status for connections to
the storage array located in the remote data center?
- A. Active Optimized
- B. Passive
- C. Active Non-optimized
- D. Standby
Answer:
C
Explanation:
Detailed Explanatio n:
Rationale for Correct Answe r:
In an HPE Peer Persistence configuration (supported on HPE Alletra MP, Primera, and 3PAR), hosts
see volumes presented from arrays at both sites. For optimal load balancing and transparent failover,
the local array paths are shown as “Active Optimized” while the remote array paths are marked
“Active Non-optimized”. The “Non-optimized” label indicates these paths are functional but involve
remote access with higher latency. This design ensures automatic transparent failover if the local site
becomes unavailable.
Distractors:
A: “Active Optimized” applies only to local array paths, not remote ones.
B: Passive paths are typical of ALUA implementations without Peer Persistence, not here.
D: “Standby” is not the term used in Peer Persistence multipathing.
Key Concept: MPIO with Peer Persistence (ALUA Active/Active configuration).
Reference: HPE Primera/Alletra Peer Persistence Best Practices Guide.
Question 4
You are meeting with a customer who wants to replace their current file storage system. You plan to
recommend HPE GreenLake for File Storage. The customer asks whether the solution can provide
cross-protocol access to the same data using both NFS and SMB simultaneously.
What is the impact on your design?
- A. A 3rd-party SDS solution such as Qumulo or Scality should be discussed since the HPE GreenLake for File Storage does not support this
- B. HPE GreenLake for File Storage supports native cross-protocol access with NFS, SMB, and S3. You must enable both protocols per share
- C. This is perfectly possible with HPE GreenLake for File Storage by creating two file shares (one for each protocol) and setting up replication
- D. Two different IP pools are required, one for each access protocol. The virtual IP pool address enables cross-protocol functionality
Answer:
B
Explanation:
Detailed Explanatio n:
Rationale for Correct Answe r:
HPE GreenLake for File Storage, powered by VAST Data software, natively supports cross-protocol
access (NFS, SMB, and S3) to the same dataset. This means a file written via NFS can be accessed via
SMB or S3 without replication. For cross-protocol access, both protocols must be enabled at the
share/bucket level. This is a core differentiator of HPE’s GreenLake for File Storage solution.
Distractors:
A: Wrong, because GreenLake for File Storage already has native multi-protocol support — no need
for 3rd party SDS.
C: Incorrect, as replication between separate shares is not required; it is a native capability.
D: Misleading — IP pools are used for load balancing and client connectivity, but not required to
enable cross-protocol access.
Key Concept: Multi-protocol access in HPE GreenLake for File Storage (NFS/SMB/S3).
Reference: HPE GreenLake for File Storage Technical Overview, VAST Data Universal Storage white
papers.
Question 5
Your organization is implementing a new high-performance computing (HPC) cluster to support
advanced scientific simul-ations. The cluster will consist of several hundred nodes that require rapid
access to shared datasets. The storage is Vast/GL4F.
The application is very sensitive to latency and minimizing CPU overhead during data transfers is
critical to achieving the desired performance levels.
Which access protocol should the organization implement to enhance NFS performance by reducing
storage latency and increasing I/O operations?
- A. NFS
- B. NFS over RDMA
- C. RoCE
- D. iSER
Answer:
B
Explanation:
Detailed Explanatio n:
Rationale for Correct Answe r:
For HPC and AI/ML workloads, NFS over RDMA (Remote Direct Memory Access) provides
significantly lower latency and reduced CPU overhead compared to standard NFS over TCP. This
allows direct memory-to-memory data transfers between storage and compute nodes, bypassing the
kernel network stack. In VAST Data (underpinning GreenLake for File Storage), NFS over RDMA is
explicitly supported to accelerate shared dataset access in HPC and AI environments.
Distractors:
A: Standard NFS introduces more latency due to kernel TCP/IP stack overhead.
C: RoCE (RDMA over Converged Ethernet) is a transport layer technology — useful, but the protocol
chosen for the file system must be NFS over RDMA, not just RoCE.
D: iSER (iSCSI Extensions for RDMA) enhances iSCSI block storage, not NFS file workloads.
Key Concept: NFS over RDMA for HPC/AI shared datasets.
Reference: HPE GreenLake for File Storage powered by VAST – HPC Deployment Guide, RDMA and
NFS performance white papers.
Question 6
You are migrating your customer's virtualization platform from an old third-party storage array to a
newly installed HPE Alletra MP B10000 array. You are using HPE Zerto Move for the migration.
Which statement is correct when using HPE Zerto Move compared to the typical Failover feature?
- A. The Zerto Checkpoint (and RPO) is user-selectable during the move
- B. The source VMs are deleted automatically after the migration
- C. You can keep the source VMs after the migration
- D. The migration results in an RPO and RTO of seconds
Answer:
C
Explanation:
Detailed Explanatio n:
Rationale for Correct Answe r:
When using Zerto Move, unlike a typical disaster recovery failover, the migration process allows the
source VMs to be retained after cutover. This is useful when testing or validating the migration. In
contrast, failover scenarios typically assume the source environment has failed or is
decommissioned. Therefore, keeping source VMs is a differentiator for Move.
Distractors:
A: Checkpoints and RPO are controlled by Zerto replication but are not selectable per migration
cutover in this way.
B: Source VMs are not deleted automatically; this is intentionally avoided to allow rollback.
D: While Zerto does provide low RPO/RTO (seconds to minutes), this applies mainly to DR failover,
not migration cutovers.
Key Concept: Zerto Move vs Zerto Failover semantics.
Reference: HPE Zerto Move Technical Overview, HPE Zerto Replication & Migration Best Practices.
Question 7
Refer to the exhibit.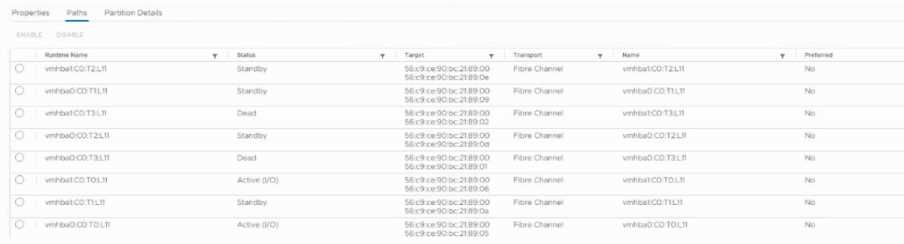
The above image represents an existing Alletra 6000 Peer Persistence configuration.
Which statement could be true in this scenario?
- A. The amount of active (0) paths could reduce the performance of the array.
- B. The performance of the array could be reduced due to the amount of paths active.
- C. The performance of the array could be reduced due to a missing controller.
Answer:
C
Explanation:
Detailed Explanatio n:
Rationale for Correct Answe r:
In the exhibit, several paths show “Standby” and some appear “Dead”, while only a subset is Active
(0). This typically indicates that one storage controller may be missing or offline, which reduces
redundancy and can cause performance degradation. In a healthy Peer Persistence environment,
both controllers should present active and non-optimized paths.
Distractors:
A & B: Having multiple active paths does not inherently reduce performance; in fact, MPIO load
balances traffic. The issue here is path failures, not excessive active paths.
Key Concept: MPIO pathing in HPE Peer Persistence and controller health.
Reference: HPE Alletra 6000 Peer Persistence Implementation Guide.
Question 8
Your customer is a regional bank with branches in two different cities. Each branch is run as an
isolated independent business and IT manages their SANs as separate fabrics to limit the scope of
any failure. They use B-Series Switches.
The customer has requested a disaster recovery option that will allow replication between the two
sites without merging the fabrics.
Which SAN technology meets the requirements?
- A. FCIP
- B. FC-FC routing
- C. NPIV
- D. Fabric partitioning
Answer:
B
Explanation:
Detailed Explanatio n:
Rationale for Correct Answe r:
FC-FC routing (also known as Fibre Channel Routing / LSANs on B-Series switches) allows replication
between separate SAN fabrics without merging them. This supports disaster recovery scenarios
while preserving fabric isolation, exactly matching the bank’s requirement.
Distractors:
A: FCIP tunnels extend Fibre Channel over IP networks, but this typically merges SAN domains.
C: NPIV (N_Port ID Virtualization) allows multiple virtual WWNs per port, not cross-fabric replication.
D: Fabric partitioning is zoning and segmentation within a single fabric, not between independent
fabrics.
Key Concept: FC-FC routing on Brocade (B-Series) for SAN isolation with replication.
Reference: HPE B-Series SAN Design Guide, Brocade FCR/LSAN Concepts.
Question 9
A junior engineer doing their first assessment makes the comment that all assessments are basically
done “entirely by the assessment tool” and all they must do is start the process in the HPE website.
You caution them that some assessment tools require a manual email by the engineer to HPE to
really start the process.
Which type of assessments require an email?
- A. Backup
- B. SAF
- C. Non-HPE
- D. CloudPhysics
Answer:
B
Explanation:
Detailed Explanatio n:
Rationale for Correct Answe r:
The SAF (Storage Assessment Framework) requires engineers to manually email the collected
assessment data to HPE for processing. This is different from fully automated tools like CloudPhysics
or Backup assessments that integrate directly with portals. This distinction is important for new
engineers performing customer assessments.
Distractors:
A: Backup assessments are usually tool-driven (StoreOnce, RMC, etc.) and automated.
C: Non-HPE assessments are outside scope and not part of HPE standard process.
D: CloudPhysics is fully automated and cloud-based — no manual email required.
Key Concept: SAF = requires manual email submission to HPE.
Reference: HPE Internal Assessment and Sizing Tools Guide.
Question 10
Your customer wants to use their HPE Alletra Storage MP B10000 array to store persistent data for
Kubernetes-based applications. After deploying the CSI driver using Helm and creating the secret
with the command kubectl create -f hpe-backed.yaml, what is the next required step to enable the
containerized applications to consume persistent volumes on the Alletra MP array?
- A. Update the Helm repository by using helm repo update to recognize the CSI driver
- B. Create a PersistentVolumeClaim by using kubectl create -f my-pvc.yaml
- C. Create a PersistentVolume by using kubectl create -f pv.yaml
- D. Define a StorageClass by running kubectl create -f storageclass.yaml
Answer:
D
Explanation:
Detailed Explanatio n:
Rationale for Correct Answe r:
After installing the HPE CSI driver and creating backend secrets, the next critical step is to define a
StorageClass that references the backend driver and parameters. Without the StorageClass,
Kubernetes cannot dynamically provision PersistentVolumes (PVs). Once the StorageClass is created,
workloads can request storage using PersistentVolumeClaims (PVCs).
Distractors:
A: Helm repo update only refreshes Helm charts; it does not enable CSI provisioning.
B: A PVC requires a StorageClass to bind dynamically — it cannot be created successfully beforehand.
C: Manually creating PVs is possible, but not the HPE best practice with CSI, which relies on
StorageClass for dynamic provisioning.
Key Concept: Kubernetes CSI workflow: Secret → StorageClass → PVC → Pod.
Question 11
Refer to the exhibit.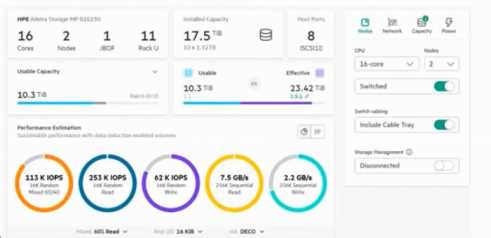
You are sizing an HPE Alletra Storage MP B10000 as shown in the graphic below.
What change must be made to the current storage configuration to achieve maximum IOPS
performance?
- A. Additional network cards or HBAs need to be added for more throughput
- B. Additional disks need to be added to the system
- C. No change needed — the system is already operating at maximum performance
- D. The controller must be upgraded to a 32-core model
Answer:
C
Explanation:
Detailed Explanatio n:
Rationale for Correct Answe r:
From the exhibit, the system shows maximum estimated IOPS performance (over 250K IOPS read,
115K IOPS mixed, 62K write). These values align with HPE’s published performance specifications for
this model with full cores enabled. The network interface count and disk count are balanced relative
to controller capability. Therefore, no further upgrades are required to achieve maximum
performance.
Distractors:
A: Adding NICs/HBAs may improve throughput but will not exceed controller-bound IOPS.
B: Adding disks increases capacity, not peak IOPS, as performance is primarily controller-driven.
D: The system already matches controller capability; upgrading cores is not an option in Alletra MP
B10000 mid-range systems.
Key Concept: Understanding performance sizing based on controller and architecture limits, not just
capacity or NICs.
Reference: HPE Alletra MP Performance and Sizing Guide.
Question 12
Which statement is true regarding HPE's SAP HANA solutions?
- A. HPE supplies custom HANA licenses exclusive for HPE appliances.
- B. Customers can reduce licensing costs with Alletra MP Block.
- C. 77% of customers prefer SAP HANA solutions on HPE.
- D. About 40% of HANA infrastructure runs on HPE.
Answer:
D
Explanation:
Detailed Explanatio n:
Rationale for Correct Answe r:
HPE is one of the leading infrastructure providers for SAP HANA, with ~40% of global SAP HANA
deployments running on HPE platforms (ProLiant, Alletra, Nimble/Primera for storage). This is an
official HPE statistic repeatedly cited in white papers and customer references.
Distractors:
A: SAP HANA licensing is provided directly by SAP, not custom-issued by HPE.
B: Licensing costs are tied to SAP metrics (memory size), not Alletra storage type.
C: “77% prefer” is a marketing exaggeration and not the accurate documented figure.
Key Concept: HPE’s strong positioning in SAP HANA infrastructure market share.
Reference: HPE SAP HANA Solutions Overview, HPE Global SAP HANA Customer Reference Sheet.
Question 13
Refer to the exhibit of Zerto Vault architecture.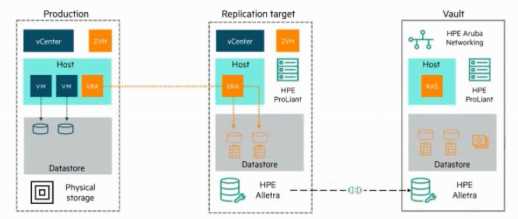
Which statement about the Zerto Vault architecture is correct?
- A. Data is replicated via encrypted periodic replication between Production and the Replication Target.
- B. Data is replicated via encrypted periodic replication between the Replication Target and the Vault.
- C. The Resilience Automation Server manages port access between Production and the Replication Target.
- D. Immutable snapshots of all Zerto components are taken at the Replication Target and replicated to the Vault.
Answer:
B
Explanation:
Detailed Explanatio n:
Rationale for Correct Answe r:
In the Zerto Vault architecture, production workloads replicate continuously to a Replication Target
(secondary site). From there, data is further replicated periodically and encrypted into the Vault (air-
gapped, isolated site). This two-step process ensures ransomware resilience and immutability, as the
Vault acts as a hardened third copy.
Distractors:
A: Production-to-replication target traffic is continuous synchronous/asynchronous replication, not
periodic. Periodic replication applies to Replication Target → Vault.
C: The Resilience Automation Server (RAS) is responsible for orchestrating failover and immutability
enforcement, but it does not control port access between production and replication target.
D: Snapshots of Zerto components are not what is replicated — it’s application data VMs/volumes.
The Vault ensures immutability of replicated data, not ZVM components.
Key Concept: Zerto Vault = encrypted, periodic replication from replication target to immutable vault.
Reference: HPE Zerto Vault Architecture White Paper, HPE Ransomware Recovery Solutions.
Question 14
A global financial services company is looking to enhance its disaster recovery (DR) capabilities. They
operate VMware workloads across multiple data centers and a mix of AWS and Azure cloud
workloads. They need a solution that can replicate data with near-zero recovery point objectives
(RPOs) and orchestrate rapid recovery of critical applications in case of a site-wide failure.
- A. Zerto
- B. CommVault
- C. Cohesity
- D. SimpliVity
Answer:
A
Explanation:
Detailed Explanatio n:
Rationale for Correct Answe r:
Zerto, now part of HPE, provides continuous data protection (CDP) with near-zero RPOs and very low
RTOs. It supports VMware workloads, as well as hybrid cloud deployments with AWS and Azure.
Zerto is specifically designed for disaster recovery orchestration, enabling automated failover,
failback, and application-consistent protection across sites and cloud environments.
Distractors:
B (CommVault): Primarily a backup/recovery and data management platform — RPOs are not near-
zero.
C (Cohesity): Strong in backup, secondary storage, and ransomware recovery, but not near-zero RPO
DR orchestration.
D (SimpliVity): Hyperconverged infrastructure with built-in backup, but not optimized for large-scale
multi-cloud DR.
Key Concept: Continuous Data Protection (Zerto) for hybrid/multi-cloud disaster recovery.
Reference: HPE Zerto DR for Hybrid and Multi-cloud Environments.
Question 15
You need to evaluate a customer virtual server environment to size an HPE Block storage solution
according to the metrics seen on the system over a period of time. The environment consists of
Lenovo servers and Pure Storage as the storage vendor for a Microsoft Hyper-V cluster managed by
Microsoft SCVMM.
Which HPE tools can you utilize to gather the usage metrics of this setup?
- A. Import the HPE CloudPhysics.vhdx collector to the Hyper-V cluster to gather the analytics.
- B. Use the HPE InfoSight Primary Storage sizing tool to calculate the competitive performance metrics.
- C. Install the SAFcollector agents into the environment and use SAFanalyze to import the agent output.
- D. Export the Microsoft System Center Virtual Machine Manager database for NinjaProtected analysis.
Answer:
A
Explanation:
Detailed Explanatio n:
Rationale for Correct Answe r:
HPE CloudPhysics provides comprehensive environment assessment and competitive sizing for
virtualized environments (VMware, Hyper-V, etc.). The CloudPhysics collector (available as a .vhdx for
Hyper-V) is deployed into the cluster to gather metrics on CPU, memory, storage IOPS/latency, and
utilization trends. These analytics feed into the sizing of HPE storage solutions.
Distractors:
B: InfoSight sizing tools work with HPE systems, not competitive 3rd-party storage like Pure.
C: SAF is a manual assessment requiring email submission and is not the correct modern method for
this case.
D: NinjaProtected applies to backup analysis, not production Hyper-V cluster sizing.
Key Concept: CloudPhysics.vhdx collector for Hyper-V sizing with 3rd-party infrastructure.
Reference: HPE CloudPhysics Assessment Guide.