HP hpe2-n69 practice test
Using HPE AI and Machine Learning
Question 1
You are helping a customer start to implement hyper parameter optimization (HPO) with HPE
Machine learning Development Environment. An ML engineer is putting together an experiment
config file with the desired Adaptive A5HA settings. The engineer asks you questions, such as how
many trials will be trained on the max length and what the min length for all trials will be.
What should you explain?
- A. The engineer should run the "det preview-search" command, referencing the experiment config.
- B. The engineer should access the HPE Machine Learning Development online calculator and input the mode, max_trials, max_length, divisor, and max_runs.
- C. The engineer should upload the experiment config to the HPE Machine Learning Development Environment WebUl and view the graph of the experiment plan.
- D. The engineer should run a preliminary experiment with one tenth the desired number of max trials, assess the results, and then run the full experiment.
Answer:
B
Explanation:
The engineer should specify the number of trials to train on the max length and the minimum length
for all trials in the experiment config file. For example, if the engineer wants to run 10 trials with a
max length of 10, the config file should look something like this:
{
"mode": "A5HA",
"max_trials": 10,
"max_length": 10,
"min_length": 1,
"divisor": 2,
"max_runs": 1
}
Once the config file is complete, the engineer should upload it to the HPE Machine Learning
Development Environment WebUI and view the graph of the experiment plan. This will allow the
engineer to see how the Adaptive A5HA settings will affect the experiment. After that, the engineer
can run the experiment and assess the results.
Question 2
A customer is using fair-share scheduling for an HPE Machine Learning Development Environment
resource pool. What is one way that users can obtain relatively more resource slots for their
important experiments?
- A. Set the weight to a higher than default value.
- B. Set the weight to a lower than default value.
- C. Set the priority to a lower than default value.
- D. Set the priority to a higher than default value.
Answer:
A
Explanation:
Fair-share scheduling allocates resources to experiments based on the weight value of the resource
pool. Increasing the weight value of a resource pool will result in more resource slots being allocated
to it.
Question 3
You want to set up a simple demo cluster for HPE Machine Learning Development Environment (or
the open source Determined Al) on Amazon Web Services (AWS). You plan to use "det deploy" to set
up the cluster. What is one prerequisite?
- A. installing the NVIDIA Container Toolkit on your local machine
- B. Manually creating the AWS EC2 instance with a PostgreSQL database
- C. Recording the name of a valid AWS EC2 keypair
- D. Adding Amazon Elastic Kubernetes Services (EKS) to your AWS account
Answer:
C
Explanation:
In order to use the "det deploy" command to set up a cluster for HPE Machine Learning
Development Environment (or the open source Determined Al) on Amazon Web Services (AWS), you
will need to have a valid AWS EC2 keypair. The keypair will authenticate your access to the cluster
and allow you to securely access the cluster once it is set up.
Question 4
A company has an HPE Machine Learning Development Environment cluster. The ML engineers store
training and validation data sets in Google Cloud Storage (GCS). What is an advantage of streaming
the data during a trial, as opposed to downloading the data?
- A. Streaming requires just one bucket, while downloading requires many.
- B. The trial can more quickly start up and begin training the model.
- C. The trial can better separate training and validation data.
- D. Setting up streaming is easier that setting up downloading.
Answer:
B
Explanation:
Streaming the data during a trial allows the data to be processed more quickly, as it does not need to
be downloaded onto the cluster before training can begin. This means that the trial can start up
faster and the model can begin training more quickly.
Question 5
Refer to the exhibit.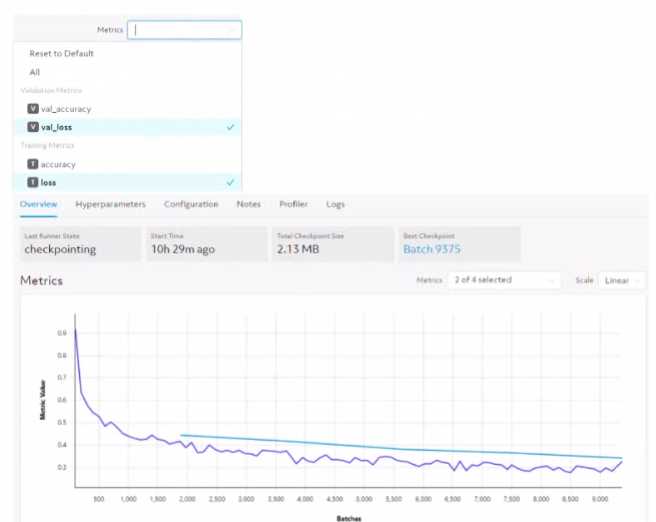
You are demonstrating HPE Machine Learning Development Environment, and you show details
about an experiment, as shown in the exhibits. The customer asks about what "validation loss'
means. What should you respond?
- A. Validation refers to testing how well the current model performs on new data; file lower the loss the better the performance.
- B. Validation refers to an assessment of how efficient the model code is; the lower the loss the lower the demand on GPU memory resources.
- C. Validation loss refers to the loss detected during the backward pass of training, while training loss refers to loss during the forward pass.
- D. Validation loss is metadata that indicates how many updates were lost between the conductor and agents.
Answer:
A
Explanation:
Validation loss is a metric used to measure how well the model is performing on unseen data. It is
calculated by taking the difference between the predicted values and the actual values. The lower
the validation loss, the better the model's performance on new data.
Question 6
An ml engineer wants to train a model on HPE Machine Learning Development Environment without
implementing hyper parameter optimization (HPO). What experiment config fields configure this
behavior?
- A. profiling: enabled: false
- B. hyperparameters; optimizer:none
- C. searcher: name: single
- D. resources: slots_per_trial: 1
Answer:
B
Explanation:
To train a model on HPE Machine Learning Development Environment without implementing hyper
parameter optimization (HPO), you need to set the "optimizer" field to "none" in the
hyperparameters section of the experiment config. This will instruct the ML engine to not use any
hyperparameter optimization when training the model.
Question 7
What is a benefit of HPE Machine Learning Development Environment, beyond open source
Determined AI?
- A. Automated user provisioning
- B. Pipeline-based data management
- C. Distributed training
- D. Automated hyperparameter optimization (HPO)
Answer:
D
Explanation:
One of the main benefits of HPE Machine Learning Development Environment is its ability to
automate the process of hyperparameter optimization (HPO). HPO is a process of automatically
tuning the hyperparameters of a model during training, which can greatly improve a model's
performance. HPE ML DE provides automated HPO, making the process of tuning and optimizing the
model much easier and more efficient.
Question 8
A customer has Men expanding its deep learning (DO prefects and is confronting several challenges.
Which of these challenges does HPE Machine Learning Development Environment specifically
address?
- A. Time-consuming data collection
- B. Complex model deployment processes
- C. Complex and time-consuming data cleansing process
- D. Complex and time-consuming hyperparameter optimization (HPO)
Answer:
D
Explanation:
The HPE Machine Learning Development Environment specifically addresses Complex and time-
consuming hyperparameter optimization (HPO). HPO is a process used to identify the most effective
set of hyperparameters for a given machine learning model. HPE's ML Development Environment
provides a suite of tools that allow users to quickly and easily design and deploy deep learning
models, as well as optimize their hyperparameters to get the best results.
Question 9
You want to set up a simple demo cluster for HPE Machine Learning Development Environment for
the open source Determined all on a local machine. Which OS Is supported?
- A. HP-UX v11i
- B. Windows Server 2016 or above
- C. Windows 10 or above
- D. Red Hat 7-based Linux
Answer:
D
Explanation:
The OS supported for setting up a simple demo cluster for HPE Machine Learning Development
Environment for the open source Determined on a local machine is Red Hat 7-based Linux. Red Hat
7-based Linux is an open source operating system that is used extensively in enterprise applications.
It provides a stable and secure platform for running applications and is suitable for use in a demo
cluster.
Question 10
The ML engineer wants to run an Adaptive ASHA experiment with hundreds of trials. The engineer
knows that several other experiments will be running on the same resource pool, and wants to avoid
taking up too large a share of resources. What can the engineer do in the experiment config file to
help support this goal?
- A. Under "searcher," set "max_concurrent_trails" to cap the number of trials run at once by this experiment.
- B. Under "searcher," set "divisor- to 2 to reduce the share of the resource slots that the experiment receives.
- C. Set the "scheduling_unit" to cap the number of resource slots used at once by this experiment.
- D. Under "resources.- set 'priority to I to reduce the share of the resource slots mat the experiment receives.
Answer:
A
Explanation:
The ML engineer can set "maxconcurrenttrials" under "searcher" in the experiment config file to cap
the number of trials run at once by this experiment. This will help ensure that the experiment does
not take up too large a share of resources, allowing other experiments to also run concurrently.
Question 11
What is a benefit or HPE Machine Learning Development Environment, beyond open source
Determined AI?
- A. Experiment tracking
- B. Model Inferencing
- C. Distributed training
- D. Premium dedicated support
Answer:
C
Explanation:
The benefit of HPE Machine Learning Development Environment beyond open source Determined AI
is Distributed Training. Distributed training allows multiple machines to train a single model in
parallel, greatly increasing the speed and efficiency of the training process. HPE ML Development
Environment provides tools and support for distributed training, allowing users to make the most of
their resources and quickly train their models.
Question 12
A customer is deploying HPE Machine learning Development Environment on on-prem
infrastructure. The customer wants to run some experiments on servers with 8 NVIDIA A too GPUs
and other experiments on servers with only Z NVIDIA T4 GPUs. What should you recommend?
- A. Letting the conductor automatically determine which servers to use for each experiment, based on the number of resource slots required
- B. Deploying two HPE Machine Learning Development Environment clusters, one tor each server type
- C. Deploying servers with 8 GPUs as agents and using the conductor to run experiments that require only 2 GPUs
- D. Establishing multiple compute resource pools on the cluster, one tor servers or each type
Answer:
D
Explanation:
By establishing multiple compute resource pools on the cluster, you can ensure that the correct
servers are used for each experiment, depending on the number of GPUs required. This will help
ensure that the experiments are run on the servers with the correct resources without having to
manually assign each experiment to the appropriate server.
Question 13
Compared to Asynchronous Successive Halving Algorithm (ASHA), what is an advantage of Adaptive
ASHA?
- A. Adaptive ASHA can handle hyperparameters related to neural architecture while ASHA cannot.
- B. ASHA selects hyperparameter configs entirely at random while Adaptive ASHA clones higher- performing configs.
- C. Adaptive ASHA can train more trials in certain amount of time, as compared to ASHA.
- D. Adaptive ASHA tries multiple exploration/exploitation tradeoffs oy running multiple Instances of ASHA.
Answer:
B
Explanation:
Adaptive ASHA is an enhanced version of ASHA that uses a reinforcement learning approach to select
hyperparameter configurations. This allows Adaptive ASHA to select higher-performing configs and
clone those configurations, allowing for better performance than ASHA.
Question 14
What is a benefit of HPE Machine Learning Development Environment mat tends to resonate with
executives?
- A. It uses a centralized training architecture that is highly efficient.
- B. It helps DL projects complete faster for a faster ROI.
- C. It helps companies deploy models and generate revenue.
- D. It automatically cleans up data to create better end results.
Answer:
B
Explanation:
HPE Machine Learning Development Environment is designed to deliver results more quickly than
traditional methods, allowing companies to get a return on their investment sooner and benefit from
their DL projects faster. This tends to be a benefit that resonates with executives, as it can help them
realize their goals more quickly and efficiently.
Question 15
Your cluster uses Amazon S3 to store checkpoints. You ran an experiment on an HPE Machine
Learning Development Environment cluster, you want to find the location tor the best checkpoint
created during the experiment. What can you do?
- A. In the experiment config that you used, look for the "bucket" field under "hyperparameters." This is the UUID for checkpoints.
- B. Use the "det experiment download -top-n I" command, referencing the experiment ID.
- C. In the Web Ul, go to the Task page and click the checkpoint task that has the experiment ID.
- D. Look for a "determined-checkpoint/" bucket within Amazon S3, referencing your experiment ID.
Answer:
D
Explanation:
HPE Machine Learning Development Environment uses Amazon S3 to store checkpoints. To find the
location of the best checkpoint created during an experiment, you need to look for a "determined-
checkpoint/" bucket within Amazon S3, referencing your experiment ID. This bucket will contain all of
the checkpoints that were created during the experiment.