databricks databricks machine learning professional practice test
Databricks Certified Machine Learning Professional
Question 1
Which of the following describes concept drift?
- A. Concept drift is when there is a change in the distribution of an input variable
- B. Concept drift is when there is a change in the distribution of a target variable
- C. Concept drift is when there is a change in the relationship between input variables and target variables
- D. Concept drift is when there is a change in the distribution of the predicted target given by the model
- E. None of these describe Concept drift
Answer:
D
Question 2
A machine learning engineer is monitoring categorical input variables for a production machine
learning application. The engineer believes that missing values are becoming more prevalent in more
recent data for a particular value in one of the categorical input variables.
Which of the following tools can the machine learning engineer use to assess their theory?
- A. Kolmogorov-Smirnov (KS) test
- B. One-way Chi-squared Test
- C. Two-way Chi-squared Test
- D. Jenson-Shannon distance
- E. None of these
Answer:
B
Question 3
A data scientist is using MLflow to track their machine learning experiment. As a part of each MLflow
run, they are performing hyperparameter tuning. The data scientist would like to have one parent
run for the tuning process with a child run for each unique combination of hyperparameter values.
They are using the following code block:
The code block is not nesting the runs in MLflow as they expected.
Which of the following changes does the data scientist need to make to the above code block so that
it successfully nests the child runs under the parent run in MLflow?
- A. Indent the child run blocks within the parent run block
- B. Add the nested=True argument to the parent run
- C. Remove the nested=True argument from the child runs
- D. Provide the same name to the run name parameter for all three run blocks
- E. Add the nested=True argument to the parent run and remove the nested=True arguments from the child runs
Answer:
E
Question 4
A machine learning engineer wants to log feature importance data from a CSV file at path
importance_path with an MLflow run for model model.
Which of the following code blocks will accomplish this task inside of an existing MLflow run block?
A.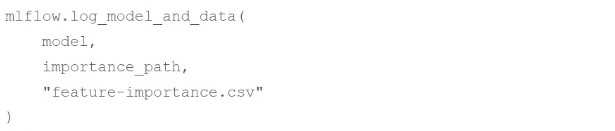
B.
C. mlflow.log_data(importance_path, "feature-importance.csv")
D. mlflow.log_artifact(importance_path, "feature-importance.csv")
E. None of these code blocks tan accomplish the task.
Answer:
A
Question 5
Which of the following is a simple, low-cost method of monitoring numeric feature drift?
- A. Jensen-Shannon test
- B. Summary statistics trends
- C. Chi-squared test
- D. None of these can be used to monitor feature drift
- E. Kolmogorov-Smirnov (KS) test
Answer:
B
Question 6
A data scientist has developed a model to predict ice cream sales using the expected temperature
and expected number of hours of sun in the day. However, the expected temperature is dropping
beneath the range of the input variable on which the model was trained.
Which of the following types of drift is present in the above scenario?
- A. Label drift
- B. None of these
- C. Concept drift
- D. Prediction drift
- E. Feature drift
Answer:
E
Question 7
A data scientist wants to remove the star_rating column from the Delta table at the location path. To
do this, they need to load in data and drop the star_rating column.
Which of the following code blocks accomplishes this task?
- A. spark.read.format(“delta”).load(path).drop(“star_rating”)
- B. spark.read.format(“delta”).table(path).drop(“star_rating”)
- C. Delta tables cannot be modified
- D. spark.read.table(path).drop(“star_rating”)
- E. spark.sql(“SELECT * EXCEPT star_rating FROM path”)
Answer:
D
Question 8
Which of the following operations in Feature Store Client fs can be used to return a Spark DataFrame
of a data set associated with a Feature Store table?
- A. fs.create_table
- B. fs.write_table
- C. fs.get_table
- D. There is no way to accomplish this task with fs
- E. fs.read_table
Answer:
A
Question 9
A machine learning engineer is in the process of implementing a concept drift monitoring solution.
They are planning to use the following steps:
1. Deploy a model to production and compute predicted values
2. Obtain the observed (actual) label values
3. _____
4. Run a statistical test to determine if there are changes over time
Which of the following should be completed as Step #3?
- A. Obtain the observed values (actual) feature values
- B. Measure the latency of the prediction time
- C. Retrain the model
- D. None of these should be completed as Step #3
- E. Compute the evaluation metric using the observed and predicted values
Answer:
D
Question 10
Which of the following is a reason for using Jensen-Shannon (JS) distance over a Kolmogorov-
Smirnov (KS) test for numeric feature drift detection?
- A. All of these reasons
- B. JS is not normalized or smoothed
- C. None of these reasons
- D. JS is more robust when working with large datasets
- E. JS does not require any manual threshold or cutoff determinations
Answer:
D
Question 11
A data scientist is utilizing MLflow to track their machine learning experiments. After completing a
series of runs for the experiment with experiment ID exp_id, the data scientist wants to
programmatically work with the experiment run data in a Spark DataFrame. They have an active
MLflow Client client and an active Spark session spark.
Which of the following lines of code can be used to obtain run-level results for exp_id in a Spark
DataFrame?
- A. client.list_run_infos(exp_id)
- B. spark.read.format("delta").load(exp_id)
- C. There is no way to programmatically return row-level results from an MLflow Experiment.
- D. mlflow.search_runs(exp_id)
- E. spark.read.format("mlflow-experiment").load(exp_id)
Answer:
B
Question 12
A data scientist has developed and logged a scikit-learn random forest model model, and then they
ended their Spark session and terminated their cluster. After starting a new cluster, they want to
review the feature_importances_ of the original model object.
Which of the following lines of code can be used to restore the model object so that
feature_importances_ is available?
- A. mlflow.load_model(model_uri)
- B. client.list_artifacts(run_id)["feature-importances.csv"]
- C. mlflow.sklearn.load_model(model_uri)
- D. This can only be viewed in the MLflow Experiments UI
- E. client.pyfunc.load_model(model_uri)
Answer:
A
Question 13
Which of the following is a simple statistic to monitor for categorical feature drift?
- A. Mode
- B. None of these
- C. Mode, number of unique values, and percentage of missing values
- D. Percentage of missing values
- E. Number of unique values
Answer:
C
Question 14
Which of the following is a probable response to identifying drift in a machine learning application?
- A. None of these responses
- B. Retraining and deploying a model on more recent data
- C. All of these responses
- D. Rebuilding the machine learning application with a new label variable
- E. Sunsetting the machine learning application
Answer:
A
Question 15
A data scientist has computed updated feature values for all primary key values stored in the Feature
Store table features. In addition, feature values for some new primary key values have also been
computed. The updated feature values are stored in the DataFrame features_df. They want to
replace all data in features with the newly computed data.
Which of the following code blocks can they use to perform this task using the Feature Store Client
fs?
A)
B)
C)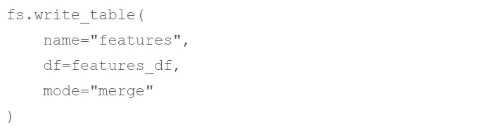
D)
E)
- A. Option A
- B. Option B
- C. Option C
- D. Option D
- E. Option E
Answer:
E