databricks databricks certified professional data engineer practice test
Databricks Certified Data Engineer Professional
Question 1
An upstream system has been configured to pass the date for a given batch of data to the Databricks
Jobs API as a parameter. The notebook to be scheduled will use this parameter to load data with the
following code:
df = spark.read.format("parquet").load(f"/mnt/source/(date)")
Which code block should be used to create the date Python variable used in the above code block?
- A. date = spark.conf.get("date")
- B. input_dict = input() date= input_dict["date"]
- C. import sys date = sys.argv[1]
- D. date = dbutils.notebooks.getParam("date")
- E. dbutils.widgets.text("date", "null") date = dbutils.widgets.get("date")
Answer:
E
Explanation:
The code block that should be used to create the date Python variable used in the above code block
is:
dbutils.widgets.text(“date”, “null”) date = dbutils.widgets.get(“date”)
This code block uses the dbutils.widgets API to create and get a text widget named “date” that can
accept a string value as a parameter1
. The default value of the widget is “null”, which means that if
no parameter is passed, the date variable will be “null”. However, if a parameter is passed through
the Databricks Jobs API, the date variable will be assigned the value of the parameter. For example, if
the parameter is “2021-11-01”, the date variable will be “2021-11-01”. This way, the notebook can
use the date variable to load data from the specified path.
The other options are not correct, because:
Option A is incorrect because spark.conf.get(“date”) is not a valid way to get a parameter passed
through the Databricks Jobs API.
The spark.conf API is used to get or set Spark configuration
properties, not notebook parameters2
.
Option B is incorrect because input() is not a valid way to get a parameter passed through the
Databricks Jobs API.
The input() function is used to get user input from the standard input stream,
not from the API request3
.
Option C is incorrect because sys.argv
is not a valid way to get a parameter passed through the
Databricks Jobs API.
The sys.argv list is used to get the command-line arguments passed to a Python
script, not to a notebook4
.
Option D is incorrect because dbutils.notebooks.getParam(“date”) is not a valid way to get a
parameter passed through the Databricks Jobs API.
The dbutils.notebooks API is used to get or set
notebook parameters when running a notebook as a job or as a subnotebook, not when passing
parameters through the API5
.
Reference:
Widgets
,
Spark Configuration
,
input()
,
sys.argv
,
Notebooks
Question 2
The Databricks workspace administrator has configured interactive clusters for each of the data
engineering groups. To control costs, clusters are set to terminate after 30 minutes of inactivity. Each
user should be able to execute workloads against their assigned clusters at any time of the day.
Assuming users have been added to a workspace but not granted any permissions, which of the
following describes the minimal permissions a user would need to start and attach to an already
configured cluster.
- A. "Can Manage" privileges on the required cluster
- B. Workspace Admin privileges, cluster creation allowed. "Can Attach To" privileges on the required cluster
- C. Cluster creation allowed. "Can Attach To" privileges on the required cluster
- D. "Can Restart" privileges on the required cluster
- E. Cluster creation allowed. "Can Restart" privileges on the required cluster
Answer:
D
Explanation:
https://learn.microsoft.com/en-us/azure/databricks/security/auth-authz/access-control/cluster-acl
https://docs.databricks.com/en/security/auth-authz/access-control/cluster-acl.html
Question 3
When scheduling Structured Streaming jobs for production, which configuration automatically
recovers from query failures and keeps costs low?
- A. Cluster: New Job Cluster; Retries: Unlimited; Maximum Concurrent Runs: Unlimited
- B. Cluster: New Job Cluster; Retries: None; Maximum Concurrent Runs: 1
- C. Cluster: Existing All-Purpose Cluster; Retries: Unlimited; Maximum Concurrent Runs: 1
- D. Cluster: New Job Cluster; Retries: Unlimited; Maximum Concurrent Runs: 1
- E. Cluster: Existing All-Purpose Cluster; Retries: None; Maximum Concurrent Runs: 1
Answer:
D
Explanation:
Maximum concurrent runs: Set to 1. There must be only one instance of each query concurrently
active. Retries: Set to Unlimited. https://docs.databricks.com/en/structured-streaming/query-recovery.html
Question 4
The data engineering team has configured a Databricks SQL query and alert to monitor the values in
a Delta Lake table. The recent_sensor_recordings table contains an identifying sensor_id alongside
the timestamp and temperature for the most recent 5 minutes of recordings.
The below query is used to create the alert: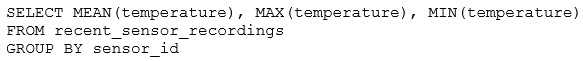
The query is set to refresh each minute and always completes in less than 10 seconds. The alert is set
to trigger when mean (temperature) > 120. Notifications are triggered to be sent at most every 1
minute.
If this alert raises notifications for 3 consecutive minutes and then stops, which statement must be
true?
- A. The total average temperature across all sensors exceeded 120 on three consecutive executions of the query
- B. The recent_sensor_recordingstable was unresponsive for three consecutive runs of the query
- C. The source query failed to update properly for three consecutive minutes and then restarted
- D. The maximum temperature recording for at least one sensor exceeded 120 on three consecutive executions of the query
- E. The average temperature recordings for at least one sensor exceeded 120 on three consecutive executions of the query
Answer:
E
Explanation:
This is the correct answer because the query is using a GROUP BY clause on the sensor_id column,
which means it will calculate the mean temperature for each sensor separately. The alert will trigger
when the mean temperature for any sensor is greater than 120, which means at least one sensor had
an average temperature above 120 for three consecutive minutes. The alert will stop when the mean
temperature for all sensors drops below 120. Verified Reference: [Databricks Certified Data Engineer
Professional], under “SQL Analytics” section; Databricks Documentation, under “Alerts” section.
Question 5
A junior developer complains that the code in their notebook isn't producing the correct results in
the development environment. A shared screenshot reveals that while they're using a notebook
versioned with Databricks Repos, they're using a personal branch that contains old logic. The desired
branch named dev-2.3.9 is not available from the branch selection dropdown.
Which approach will allow this developer to review the current logic for this notebook?
- A. Use Repos to make a pull request use the Databricks REST API to update the current branch to dev-2.3.9
- B. Use Repos to pull changes from the remote Git repository and select the dev-2.3.9 branch.
- C. Use Repos to checkout the dev-2.3.9 branch and auto-resolve conflicts with the current branch
- D. Merge all changes back to the main branch in the remote Git repository and clone the repo again
- E. Use Repos to merge the current branch and the dev-2.3.9 branch, then make a pull request to sync with the remote repository
Answer:
B
Explanation:
This is the correct answer because it will allow the developer to update their local repository with
the latest changes from the remote repository and switch to the desired branch. Pulling changes will
not affect the current branch or create any conflicts, as it will only fetch the changes and not merge
them. Selecting the dev-2.3.9 branch from the dropdown will checkout that branch and display its
contents in the notebook. Verified Reference: [Databricks Certified Data Engineer Professional],
under “Databricks Tooling” section; Databricks Documentation, under “Pull changes from a remote
repository” section.
Question 6
The security team is exploring whether or not the Databricks secrets module can be leveraged for
connecting to an external database.
After testing the code with all Python variables being defined with strings, they upload the password
to the secrets module and configure the correct permissions for the currently active user. They then
modify their code to the following (leaving all other variables unchanged).
Which statement describes what will happen when the above code is executed?
- A. The connection to the external table will fail; the string "redacted" will be printed.
- B. An interactive input box will appear in the notebook; if the right password is provided, the connection will succeed and the encoded password will be saved to DBFS.
- C. An interactive input box will appear in the notebook; if the right password is provided, the connection will succeed and the password will be printed in plain text.
- D. The connection to the external table will succeed; the string value of password will be printed in plain text.
- E. The connection to the external table will succeed; the string "redacted" will be printed.
Answer:
E
Explanation:
This is the correct answer because the code is using the dbutils.secrets.get method to retrieve the
password from the secrets module and store it in a variable. The secrets module allows users to
securely store and access sensitive information such as passwords, tokens, or API keys. The
connection to the external table will succeed because the password variable will contain the actual
password value. However, when printing the password variable, the string “redacted” will be
displayed instead of the plain text password, as a security measure to prevent exposing sensitive
information in notebooks. Verified Reference: [Databricks Certified Data Engineer Professional],
under “Security & Governance” section; Databricks Documentation, under “Secrets” section.
Question 7
The data science team has created and logged a production model using MLflow. The following code
correctly imports and applies the production model to output the predictions as a new DataFrame
named preds with the schema "customer_id LONG, predictions DOUBLE, date DATE".
The data science team would like predictions saved to a Delta Lake table with the ability to compare
all predictions across time. Churn predictions will be made at most once per day.
Which code block accomplishes this task while minimizing potential compute costs?
A) preds.write.mode("append").saveAsTable("churn_preds")
B) preds.write.format("delta").save("/preds/churn_preds")
C)
D)
E)
- A. Option A
- B. Option B
- C. Option C
- D. Option D
- E. Option E
Answer:
A
Question 8
An upstream source writes Parquet data as hourly batches to directories named with the current
date. A nightly batch job runs the following code to ingest all data from the previous day as indicated
by the date variable:
Assume that the fields customer_id and order_id serve as a composite key to uniquely identify each
order.
If the upstream system is known to occasionally produce duplicate entries for a single order hours
apart, which statement is correct?
- A. Each write to the orders table will only contain unique records, and only those records without duplicates in the target table will be written.
- B. Each write to the orders table will only contain unique records, but newly written records may have duplicates already present in the target table.
- C. Each write to the orders table will only contain unique records; if existing records with the same key are present in the target table, these records will be overwritten.
- D. Each write to the orders table will only contain unique records; if existing records with the same key are present in the target table, the operation will tail.
- E. Each write to the orders table will run deduplication over the union of new and existing records, ensuring no duplicate records are present.
Answer:
B
Explanation:
This is the correct answer because the code uses the dropDuplicates method to remove any
duplicate records within each batch of data before writing to the orders table. However, this method
does not check for duplicates across different batches or in the target table, so it is possible that
newly written records may have duplicates already present in the target table. To avoid this, a better
approach would be to use Delta Lake and perform an upsert operation using mergeInto. Verified
Reference: [Databricks Certified Data Engineer Professional], under “Delta Lake” section; Databricks
Documentation, under “DROP DUPLICATES” section.
Question 9
A junior member of the data engineering team is exploring the language interoperability of
Databricks notebooks. The intended outcome of the below code is to register a view of all sales that
occurred in countries on the continent of Africa that appear in the geo_lookup table.
Before executing the code, running SHOW TABLES on the current database indicates the database
contains only two tables: geo_lookup and sales.
Which statement correctly describes the outcome of executing these command cells in order in an
interactive notebook?
- A. Both commands will succeed. Executing show tables will show that countries at and sales at have been registered as views.
- B. Cmd 1 will succeed. Cmd 2 will search all accessible databases for a table or view named countries af: if this entity exists, Cmd 2 will succeed.
- C. Cmd 1 will succeed and Cmd 2 will fail, countries at will be a Python variable representing a PySpark DataFrame.
- D. Both commands will fail. No new variables, tables, or views will be created.
- E. Cmd 1 will succeed and Cmd 2 will fail, countries at will be a Python variable containing a list of strings.
Answer:
E
Explanation:
This is the correct answer because Cmd 1 is written in Python and uses a list comprehension to
extract the country names from the geo_lookup table and store them in a Python variable named
countries af. This variable will contain a list of strings, not a PySpark DataFrame or a SQL view. Cmd 2
is written in SQL and tries to create a view named sales af by selecting from the sales table where
city is in countries af. However, this command will fail because countries af is not a valid SQL entity
and cannot be used in a SQL query. To fix this, a better approach would be to use spark.sql() to
execute a SQL query in Python and pass the countries af variable as a parameter. Verified Reference:
[Databricks Certified Data Engineer Professional], under “Language Interoperability” section;
Databricks Documentation, under “Mix languages” section.
Question 10
A Delta table of weather records is partitioned by date and has the below schema:
date DATE, device_id INT, temp FLOAT, latitude FLOAT, longitude FLOAT
To find all the records from within the Arctic Circle, you execute a query with the below filter:
latitude > 66.3
Which statement describes how the Delta engine identifies which files to load?
- A. All records are cached to an operational database and then the filter is applied
- B. The Parquet file footers are scanned for min and max statistics for the latitude column
- C. All records are cached to attached storage and then the filter is applied
- D. The Delta log is scanned for min and max statistics for the latitude column
- E. The Hive metastore is scanned for min and max statistics for the latitude column
Answer:
D
Explanation:
This is the correct answer because Delta Lake uses a transaction log to store metadata about each
table, including min and max statistics for each column in each data file. The Delta engine can use
this information to quickly identify which files to load based on a filter condition, without scanning
the entire table or the file footers. This is called data skipping and it can improve query performance
significantly. Verified Reference: [Databricks Certified Data Engineer Professional], under “Delta
Lake” section; [Databricks Documentation], under “Optimizations - Data Skipping” section.
In the Transaction log, Delta Lake captures statistics for each data file of the table. These statistics
indicate per file:
- Total number of records
- Minimum value in each column of the first 32 columns of the table
- Maximum value in each column of the first 32 columns of the table
- Null value counts for in each column of the first 32 columns of the table
When a query with a selective filter is executed against the table, the query optimizer uses these
statistics to generate the query result. it leverages them to identify data files that may contain
records matching the conditional filter.
For the SELECT query in the question, The transaction log is scanned for min and max statistics for the
price column
Question 11
The data engineering team has configured a job to process customer requests to be forgotten (have
their data deleted). All user data that needs to be deleted is stored in Delta Lake tables using default
table settings.
The team has decided to process all deletions from the previous week as a batch job at 1am each
Sunday. The total duration of this job is less than one hour. Every Monday at 3am, a batch job
executes a series of VACUUM commands on all Delta Lake tables throughout the organization.
The compliance officer has recently learned about Delta Lake's time travel functionality. They are
concerned that this might allow continued access to deleted data.
Assuming all delete logic is correctly implemented, which statement correctly addresses this
concern?
- A. Because the vacuum command permanently deletes all files containing deleted records, deleted records may be accessible with time travel for around 24 hours.
- B. Because the default data retention threshold is 24 hours, data files containing deleted records will be retained until the vacuum job is run the following day.
- C. Because Delta Lake time travel provides full access to the entire history of a table, deleted records can always be recreated by users with full admin privileges.
- D. Because Delta Lake's delete statements have ACID guarantees, deleted records will be permanently purged from all storage systems as soon as a delete job completes.
- E. Because the default data retention threshold is 7 days, data files containing deleted records will be retained until the vacuum job is run 8 days later.
Answer:
E
Explanation:
https://learn.microsoft.com/en-us/azure/databricks/delta/vacuum
Question 12
A junior data engineer has configured a workload that posts the following JSON to the Databricks
REST API endpoint 2.0/jobs/create.
Assuming that all configurations and referenced resources are available, which statement describes
the result of executing this workload three times?
- A. Three new jobs named "Ingest new data" will be defined in the workspace, and they will each run once daily.
- B. The logic defined in the referenced notebook will be executed three times on new clusters with the configurations of the provided cluster ID.
- C. Three new jobs named "Ingest new data" will be defined in the workspace, but no jobs will be executed.
- D. One new job named "Ingest new data" will be defined in the workspace, but it will not be executed.
- E. The logic defined in the referenced notebook will be executed three times on the referenced existing all purpose cluster.
Answer:
C
Explanation:
This is the correct answer because the JSON posted to the Databricks REST API endpoint
2.0/jobs/create defines a new job with a name, an existing cluster id, and a notebook task. However,
it does not specify any schedule or trigger for the job execution. Therefore, three new jobs with the
same name and configuration will be created in the workspace, but none of them will be executed
until they are manually triggered or scheduled. Verified Reference: [Databricks Certified Data
Engineer Professional], under “Monitoring & Logging” section; [Databricks Documentation], under
“Jobs API - Create” section.
Question 13
An upstream system is emitting change data capture (CDC) logs that are being written to a cloud
object storage directory. Each record in the log indicates the change type (insert, update, or delete)
and the values for each field after the change. The source table has a primary key identified by the
field pk_id.
For auditing purposes, the data governance team wishes to maintain a full record of all values that
have ever been valid in the source system. For analytical purposes, only the most recent value for
each record needs to be recorded. The Databricks job to ingest these records occurs once per hour,
but each individual record may have changed multiple times over the course of an hour.
Which solution meets these requirements?
- A. Create a separate history table for each pk_id resolve the current state of the table by running a union all filtering the history tables for the most recent state.
- B. Use merge into to insert, update, or delete the most recent entry for each pk_id into a bronze table, then propagate all changes throughout the system.
- C. Iterate through an ordered set of changes to the table, applying each in turn; rely on Delta Lake's versioning ability to create an audit log.
- D. Use Delta Lake's change data feed to automatically process CDC data from an external system, propagating all changes to all dependent tables in the Lakehouse.
- E. Ingest all log information into a bronze table; use merge into to insert, update, or delete the most recent entry for each pk_id into a silver table to recreate the current table state.
Answer:
E
Explanation:
This is the correct answer because it meets the requirements of maintaining a full record of all values
that have ever been valid in the source system and recreating the current table state with only the
most recent value for each record. The code ingests all log information into a bronze table, which
preserves the raw CDC data as it is. Then, it uses merge into to perform an upsert operation on a
silver table, which means it will insert new records or update or delete existing records based on the
change type and the pk_id columns. This way, the silver table will always reflect the current state of
the source table, while the bronze table will keep the history of all changes. Verified Reference:
[Databricks Certified Data Engineer Professional], under “Delta Lake” section; Databricks
Documentation, under “Upsert into a table using merge” section.
Question 14
An hourly batch job is configured to ingest data files from a cloud object storage container where
each batch represent all records produced by the source system in a given hour. The batch job to
process these records into the Lakehouse is sufficiently delayed to ensure no late-arriving data is
missed. The user_id field represents a unique key for the data, which has the following schema:
user_id BIGINT, username STRING, user_utc STRING, user_region STRING, last_login BIGINT,
auto_pay BOOLEAN, last_updated BIGINT
New records are all ingested into a table named account_history which maintains a full record of all
data in the same schema as the source. The next table in the system is named account_current and is
implemented as a Type 1 table representing the most recent value for each unique user_id.
Assuming there are millions of user accounts and tens of thousands of records processed hourly,
which implementation can be used to efficiently update the described account_current table as part
of each hourly batch job?
- A. Use Auto Loader to subscribe to new files in the account history directory; configure a Structured Streaminq trigger once job to batch update newly detected files into the account current table.
- B. Overwrite the account current table with each batch using the results of a query against the account history table grouping by user id and filtering for the max value of last updated.
- C. Filter records in account history using the last updated field and the most recent hour processed, as well as the max last iogin by user id write a merge statement to update or insert the most recent value for each user id.
- D. Use Delta Lake version history to get the difference between the latest version of account history and one version prior, then write these records to account current.
- E. Filter records in account history using the last updated field and the most recent hour processed, making sure to deduplicate on username; write a merge statement to update or insert the most recent value for each username.
Answer:
C
Explanation:
This is the correct answer because it efficiently updates the account current table with only the most
recent value for each user id. The code filters records in account history using the last updated field
and the most recent hour processed, which means it will only process the latest batch of data. It also
filters by the max last login by user id, which means it will only keep the most recent record for each
user id within that batch. Then, it writes a merge statement to update or insert the most recent value
for each user id into account current, which means it will perform an upsert operation based on the
user id column. Verified Reference: [Databricks Certified Data Engineer Professional], under “Delta
Lake” section; Databricks Documentation, under “Upsert into a table using merge” section.
Question 15
A table in the Lakehouse named customer_churn_params is used in churn prediction by the machine
learning team. The table contains information about customers derived from a number of upstream
sources. Currently, the data engineering team populates this table nightly by overwriting the table
with the current valid values derived from upstream data sources.
The churn prediction model used by the ML team is fairly stable in production. The team is only
interested in making predictions on records that have changed in the past 24 hours.
Which approach would simplify the identification of these changed records?
- A. Apply the churn model to all rows in the customer_churn_params table, but implement logic to perform an upsert into the predictions table that ignores rows where predictions have not changed.
- B. Convert the batch job to a Structured Streaming job using the complete output mode; configure a Structured Streaming job to read from the customer_churn_params table and incrementally predict against the churn model.
- C. Calculate the difference between the previous model predictions and the current customer_churn_params on a key identifying unique customers before making new predictions; only make predictions on those customers not in the previous predictions.
- D. Modify the overwrite logic to include a field populated by calling spark.sql.functions.current_timestamp() as data are being written; use this field to identify records written on a particular date.
- E. Replace the current overwrite logic with a merge statement to modify only those records that have changed; write logic to make predictions on the changed records identified by the change data feed.
Answer:
E
Explanation:
The approach that would simplify the identification of the changed records is to replace the current
overwrite logic with a merge statement to modify only those records that have changed, and write
logic to make predictions on the changed records identified by the change data feed.
This approach
leverages the Delta Lake features of merge and change data feed, which are designed to handle
upserts and track row-level changes in a Delta table12
. By using merge, the data engineering team
can avoid overwriting the entire table every night, and only update or insert the records that have
changed in the source data. By using change data feed, the ML team can easily access the change
events that have occurred in the customer_churn_params table, and filter them by operation type
(update or insert) and timestamp. This way, they can only make predictions on the records that have
changed in the past 24 hours, and avoid re-processing the unchanged records.
The other options are not as simple or efficient as the proposed approach, because:
Option A would require applying the churn model to all rows in the customer_churn_params table,
which would be wasteful and redundant. It would also require implementing logic to perform an
upsert into the predictions table, which would be more complex than using the merge statement.
Option B would require converting the batch job to a Structured Streaming job, which would involve
changing the data ingestion and processing logic. It would also require using the complete output
mode, which would output the entire result table every time there is a change in the source data,
which would be inefficient and costly.
Option C would require calculating the difference between the previous model predictions and the
current customer_churn_params on a key identifying unique customers, which would be
computationally expensive and prone to errors. It would also require storing and accessing the
previous predictions, which would add extra storage and I/O costs.
Option D would require modifying the overwrite logic to include a field populated by calling
spark.sql.functions.current_timestamp() as data are being written, which would add extra complexity
and overhead to the data engineering job. It would also require using this field to identify records
written on a particular date, which would be less accurate and reliable than using the change data
feed.
Reference:
Merge
,
Change data feed