databricks databricks certified associate developer for apache spark 3 5 practice test
Databricks Certified Associate Developer for Apache Spark 3.5 - Python
Question 1
A data scientist of an e-commerce company is working with user data obtained from its subscriber
database and has stored the data in a DataFrame df_user. Before further processing the data, the
data scientist wants to create another DataFrame df_user_non_pii and store only the non-PII
columns in this DataFrame. The PII columns in df_user are first_name, last_name, email, and
birthdate.
Which code snippet can be used to meet this requirement?
- B. df_user_non_pii = df_user.drop("first_name", "last_name", "email", "birthdate")
- C. df_user_non_pii = df_user.dropfields("first_name", "last_name", "email", "birthdate")
- D. df_user_non_pii = df_user.dropfields("first_name, last_name, email, birthdate")
Answer:
A
Explanation:
To remove specific columns from a PySpark DataFrame, the drop() method is used. This method
returns a new DataFrame without the specified columns. The correct syntax for dropping multiple
columns is to pass each column name as a separate argument to the drop() method.
Correct Usage:
df_user_non_pii = df_user.drop("first_name", "last_name", "email", "birthdate")
This line of code will return a new DataFrame df_user_non_pii that excludes the specified PII
columns.
Explanation of Options:
A . Correct. Uses the drop() method with multiple column names passed as separate arguments,
which is the standard and correct usage in PySpark.
B . Although it appears similar to Option A, if the column names are not enclosed in quotes or if
there's a syntax error (e.g., missing quotes or incorrect variable names), it would result in an error.
However, as written, it's identical to Option A and thus also correct.
C . Incorrect. The dropfields() method is not a method of the DataFrame class in PySpark. It's used
with StructType columns to drop fields from nested structures, not top-level DataFrame columns.
D . Incorrect. Passing a single string with comma-separated column names to dropfields() is not valid
syntax in PySpark.
Reference:
PySpark Documentation:
DataFrame.drop
Stack Overflow Discussion:
How to delete columns in PySpark DataFrame
Question 2
A data engineer is working on a Streaming DataFrame streaming_df with the given streaming data: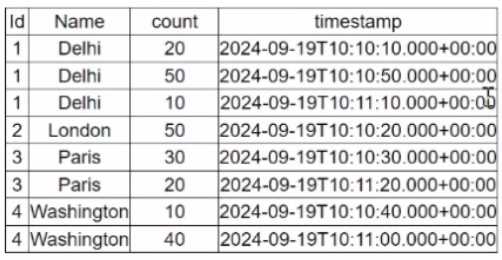
Which operation is supported with streamingdf ?
- A. streaming_df. select (countDistinct ("Name") )
- B. streaming_df.groupby("Id") .count ()
- C. streaming_df.orderBy("timestamp").limit(4)
- D. streaming_df.filter (col("count") < 30).show()
Answer:
D
Explanation:
Which operation is supported with streaming_df?
A. streaming_df.select(countDistinct("Name"))
B. streaming_df.groupby("Id").count()
C. streaming_df.orderBy("timestamp").limit(4)
D. streaming_df.filter(col("count") < 30).show()
Answer: B
Explanation:
In Structured Streaming, only a limited subset of operations is supported due to the nature of
unbounded data. Operations like sorting (orderBy) and global aggregation (countDistinct) require a
full view of the dataset, which is not possible with streaming data unless specific watermarks or
windows are defined.
Review of Each Option:
A . select(countDistinct("Name"))
Not allowed — Global aggregation like countDistinct() requires the full dataset and is not supported
directly in streaming without watermark and windowing logic.
Reference: Databricks Structured Streaming Guide – Unsupported Operations.
B . groupby("Id").count()
Supported — Streaming aggregations over a key (like groupBy("Id")) are supported. Spark maintains
intermediate state for each key.
Reference: Databricks Docs → Aggregations in Structured Streaming
(https://docs.databricks.com/structured-streaming/aggregation.html)
C . orderBy("timestamp").limit(4)
Not allowed — Sorting and limiting require a full view of the stream (which is infinite), so this is
unsupported in streaming DataFrames.
Reference: Spark Structured Streaming – Unsupported Operations (ordering without
watermark/window not allowed).
D . filter(col("count") < 30).show()
Not allowed — show() is a blocking operation used for debugging batch DataFrames; it's not allowed
on streaming DataFrames.
Reference: Structured Streaming Programming Guide – Output operations like show() are not
supported.
Reference Extract from Official Guide:
“Operations like orderBy, limit, show, and countDistinct are not supported in Structured Streaming
because they require the full dataset to compute a result. Use groupBy(...).agg(...) instead for
incremental aggregations.”
— Databricks Structured Streaming Programming Guide
Question 3
An MLOps engineer is building a Pandas UDF that applies a language model that translates English
strings into Spanish. The initial code is loading the model on every call to the UDF, which is hurting
the performance of the data pipeline.
The initial code is:
def in_spanish_inner(df: pd.Series) -> pd.Series:
model = get_translation_model(target_lang='es')
return df.apply(model)
in_spanish = sf.pandas_udf(in_spanish_inner, StringType())
How can the MLOps engineer change this code to reduce how many times the language model is
loaded?
- A. Convert the Pandas UDF to a PySpark UDF
- B. Convert the Pandas UDF from a Series → Series UDF to a Series → Scalar UDF
- C. Run the in_spanish_inner() function in a mapInPandas() function call
- D. Convert the Pandas UDF from a Series → Series UDF to an Iterator[Series] → Iterator[Series] UDF
Answer:
D
Explanation:
The provided code defines a Pandas UDF of type Series-to-Series, where a new instance of the
language model is created on each call, which happens per batch. This is inefficient and results in
significant overhead due to repeated model initialization.
To reduce the frequency of model loading, the engineer should convert the UDF to an iterator-based
Pandas UDF (Iterator[pd.Series] -> Iterator[pd.Series]). This allows the model to be loaded once per
executor and reused across multiple batches, rather than once per call.
From the official Databricks documentation:
“Iterator of Series to Iterator of Series UDFs are useful when the UDF initialization is expensive… For
example, loading a ML model once per executor rather than once per row/batch.”
— Databricks Official Docs: Pandas UDFs
Correct implementation looks like:
python
CopyEdit
@pandas_udf("string")
def translate_udf(batch_iter: Iterator[pd.Series]) -> Iterator[pd.Series]:
model = get_translation_model(target_lang='es')
for batch in batch_iter:
yield batch.apply(model)
This refactor ensures the get_translation_model() is invoked once per executor process, not per
batch, significantly improving pipeline performance.
Question 4
A Spark DataFrame df is cached using the MEMORY_AND_DISK storage level, but the DataFrame is
too large to fit entirely in memory.
What is the likely behavior when Spark runs out of memory to store the DataFrame?
- A. Spark duplicates the DataFrame in both memory and disk. If it doesn't fit in memory, the DataFrame is stored and retrieved from the disk entirely.
- B. Spark splits the DataFrame evenly between memory and disk, ensuring balanced storage utilization.
- C. Spark will store as much data as possible in memory and spill the rest to disk when memory is full, continuing processing with performance overhead.
- D. Spark stores the frequently accessed rows in memory and less frequently accessed rows on disk, utilizing both resources to offer balanced performance.
Answer:
C
Explanation:
When using the MEMORY_AND_DISK storage level, Spark attempts to cache as much of the
DataFrame in memory as possible. If the DataFrame does not fit entirely in memory, Spark will store
the remaining partitions on disk. This allows processing to continue, albeit with a performance
overhead due to disk I/O.
As per the Spark documentation:
"MEMORY_AND_DISK: It stores partitions that do not fit in memory on disk and keeps the rest in
memory. This can be useful when working with datasets that are larger than the available memory."
— Perficient Blogs: Spark - StorageLevel
This behavior ensures that Spark can handle datasets larger than the available memory by spilling
excess data to disk, thus preventing job failures due to memory constraints.
Question 5
A data engineer is building a Structured Streaming pipeline and wants the pipeline to recover from
failures or intentional shutdowns by continuing where the pipeline left off.
How can this be achieved?
- A. By configuring the option checkpointLocation during readStream
- B. By configuring the option recoveryLocation during the SparkSession initialization
- C. By configuring the option recoveryLocation during writeStream
- D. By configuring the option checkpointLocation during writeStream
Answer:
D
Explanation:
To enable a Structured Streaming query to recover from failures or intentional shutdowns, it is
essential to specify the checkpointLocation option during the writeStream operation. This checkpoint
location stores the progress information of the streaming query, allowing it to resume from where it
left off.
According to the Databricks documentation:
"You must specify the checkpointLocation option before you run a streaming query, as in the
following example:
.option("checkpointLocation", "/path/to/checkpoint/dir")
.toTable("catalog.schema.table")
— Databricks Documentation: Structured Streaming checkpoints
By setting the checkpointLocation during writeStream, Spark can maintain state information and
ensure exactly-once processing semantics, which are crucial for reliable streaming applications.
Question 6
A data scientist is analyzing a large dataset and has written a PySpark script that includes several
transformations and actions on a DataFrame. The script ends with a collect() action to retrieve the
results.
How does Apache Spark™'s execution hierarchy process the operations when the data scientist runs
this script?
- A. The script is first divided into multiple applications, then each application is split into jobs, stages, and finally tasks.
- B. The entire script is treated as a single job, which is then divided into multiple stages, and each stage is further divided into tasks based on data partitions.
- C. The collect() action triggers a job, which is divided into stages at shuffle boundaries, and each stage is split into tasks that operate on individual data partitions.
- D. Spark creates a single task for each transformation and action in the script, and these tasks are grouped into stages and jobs based on their dependencies.
Answer:
C
Explanation:
In Apache Spark, the execution hierarchy is structured as follows:
Application: The highest-level unit, representing the user program built on Spark.
Job: Triggered by an action (e.g., collect(), count()). Each action corresponds to a job.
Stage: A job is divided into stages based on shuffle boundaries. Each stage contains tasks that can be
executed in parallel.
Task: The smallest unit of work, representing a single operation applied to a partition of the data.
When the collect() action is invoked, Spark initiates a job. This job is then divided into stages at
points where data shuffling is required (i.e., wide transformations). Each stage comprises tasks that
are distributed across the cluster's executors, operating on individual data partitions.
This hierarchical execution model allows Spark to efficiently process large-scale data by parallelizing
tasks and optimizing resource utilization.
Question 7
A developer is trying to join two tables, sales.purchases_fct and sales.customer_dim, using the
following code:
fact_df = purch_df.join(cust_df, F.col('customer_id') == F.col('custid'))
The developer has discovered that customers in the purchases_fct table that do not exist in the
customer_dim table are being dropped from the joined table.
Which change should be made to the code to stop these customer records from being dropped?
- A. fact_df = purch_df.join(cust_df, F.col('customer_id') == F.col('custid'), 'left')
- B. fact_df = cust_df.join(purch_df, F.col('customer_id') == F.col('custid'))
- C. fact_df = purch_df.join(cust_df, F.col('cust_id') == F.col('customer_id'))
- D. fact_df = purch_df.join(cust_df, F.col('customer_id') == F.col('custid'), 'right_outer')
Answer:
A
Explanation:
In Spark, the default join type is an inner join, which returns only the rows with matching keys in
both DataFrames. To retain all records from the left DataFrame (purch_df) and include matching
records from the right DataFrame (cust_df), a left outer join should be used.
By specifying the join type as 'left', the modified code ensures that all records from purch_df are
preserved, and matching records from cust_df are included. Records in purch_df without a
corresponding match in cust_df will have null values for the columns from cust_df.
This approach is consistent with standard SQL join operations and is supported in PySpark's
DataFrame API.
Question 8
A data engineer is reviewing a Spark application that applies several transformations to a DataFrame
but notices that the job does not start executing immediately.
Which two characteristics of Apache Spark's execution model explain this behavior?
Choose 2 answers:
- A. The Spark engine requires manual intervention to start executing transformations.
- B. Only actions trigger the execution of the transformation pipeline.
- C. Transformations are executed immediately to build the lineage graph.
- D. The Spark engine optimizes the execution plan during the transformations, causing delays.
- E. Transformations are evaluated lazily.
Answer:
B, E
Explanation:
Apache Spark employs a lazy evaluation model for transformations. This means that when
transformations (e.g., map(), filter()) are applied to a DataFrame, Spark does not execute them
immediately. Instead, it builds a logical plan (lineage) of transformations to be applied.
Execution is deferred until an action (e.g., collect(), count(), save()) is called. At that point, Spark's
Catalyst optimizer analyzes the logical plan, optimizes it, and then executes the physical plan to
produce the result.
This lazy evaluation strategy allows Spark to optimize the execution plan, minimize data shuffling,
and improve overall performance by reducing unnecessary computations.
Question 9
A developer needs to produce a Python dictionary using data stored in a small Parquet table, which
looks like this:
The resulting Python dictionary must contain a mapping of region -> region id containing the smallest
3 region_id values.
Which code fragment meets the requirements?
A)
B)
C)
D)
The resulting Python dictionary must contain a mapping of region -> region_id for the smallest 3
region_id values.
Which code fragment meets the requirements?
A.
regions = dict(
regions_df
.select('region', 'region_id')
.sort('region_id')
.take(3)
)
B.
regions = dict(
regions_df
.select('region_id', 'region')
.sort('region_id')
.take(3)
)
C.
regions = dict(
regions_df
.select('region_id', 'region')
.limit(3)
.collect()
)
D.
regions = dict(
regions_df
.select('region', 'region_id')
.sort(desc('region_id'))
.take(3)
)
- A. Option A
- B. Option B
- C. Option C
- D. Option D
Answer:
A
Explanation:
The question requires creating a dictionary where keys are region values and values are the
corresponding region_id integers. Furthermore, it asks to retrieve only the smallest 3 region_id
values.
Key observations:
.select('region', 'region_id') puts the column order as expected by dict() — where the first column
becomes the key and the second the value.
.sort('region_id') ensures sorting in ascending order so the smallest IDs are first.
.take(3) retrieves exactly 3 rows.
Wrapping the result in dict(...) correctly builds the required Python dictionary: { 'AFRICA': 0,
'AMERICA': 1, 'ASIA': 2 }.
Incorrect options:
Option B flips the order to region_id first, resulting in a dictionary with integer keys — not what's
asked.
Option C uses .limit(3) without sorting, which leads to non-deterministic rows based on partition
layout.
Option D sorts in descending order, giving the largest rather than smallest region_ids.
Hence, Option A meets all the requirements precisely.
Question 10
An engineer has a large ORC file located at /file/test_data.orc and wants to read only specific
columns to reduce memory usage.
Which code fragment will select the columns, i.e., col1, col2, during the reading process?
- A. spark.read.orc("/file/test_data.orc").filter("col1 = 'value' ").select("col2")
- B. spark.read.format("orc").select("col1", "col2").load("/file/test_data.orc")
- C. spark.read.orc("/file/test_data.orc").selected("col1", "col2")
- D. spark.read.format("orc").load("/file/test_data.orc").select("col1", "col2")
Answer:
D
Explanation:
The correct way to load specific columns from an ORC file is to first load the file using .load() and then
apply .select() on the resulting DataFrame. This is valid with .read.format("orc") or the shortcut
.read.orc().
df = spark.read.format("orc").load("/file/test_data.orc").select("col1", "col2")
Why others are incorrect:
A performs selection after filtering, but doesn’t match the intention to minimize memory at load.
B incorrectly tries to use .select() before .load(), which is invalid.
C uses a non-existent .selected() method.
D correctly loads and then selects.
Reference:
Apache Spark SQL API - ORC Format
Question 11
Given the code fragment:
import pyspark.pandas as ps
psdf = ps.DataFrame({'col1': [1, 2], 'col2': [3, 4]})
Which method is used to convert a Pandas API on Spark DataFrame (pyspark.pandas.DataFrame) into
a standard PySpark DataFrame (pyspark.sql.DataFrame)?
- A. psdf.to_spark()
- B. psdf.to_pyspark()
- C. psdf.to_pandas()
- D. psdf.to_dataframe()
Answer:
A
Explanation:
Pandas API on Spark (pyspark.pandas) allows interoperability with PySpark DataFrames. To convert a
pyspark.pandas.DataFrame to a standard PySpark DataFrame, you use .to_spark().
Example:
df = psdf.to_spark()
This is the officially supported method as per Databricks Documentation.
Incorrect options:
B, D: Invalid or nonexistent methods.
C: Converts to a local pandas DataFrame, not a PySpark DataFrame.
Question 12
A Spark engineer is troubleshooting a Spark application that has been encountering out-of-memory
errors during execution. By reviewing the Spark driver logs, the engineer notices multiple "GC
overhead limit exceeded" messages.
Which action should the engineer take to resolve this issue?
- A. Optimize the data processing logic by repartitioning the DataFrame.
- B. Modify the Spark configuration to disable garbage collection
- C. Increase the memory allocated to the Spark Driver.
- D. Cache large DataFrames to persist them in memory.
Answer:
C
Explanation:
The message "GC overhead limit exceeded" typically indicates that the JVM is spending too much
time in garbage collection with little memory recovery. This suggests that the driver or executor is
under-provisioned in memory.
The most effective remedy is to increase the driver memory using:
--driver-memory 4g
This is confirmed in Spark's official troubleshooting documentation:
“If you see a lot of GC overhead limit exceeded errors in the driver logs, it’s a sign that the driver is
running out of memory.”
—
Spark Tuning Guide
Why others are incorrect:
A may help but does not directly address the driver memory shortage.
B is not a valid action; GC cannot be disabled.
D increases memory usage, worsening the problem.
Question 13
A DataFrame df has columns name, age, and salary. The developer needs to sort the DataFrame by
age in ascending order and salary in descending order.
Which code snippet meets the requirement of the developer?
- A. df.orderBy(col("age").asc(), col("salary").asc()).show()
- B. df.sort("age", "salary", ascending=[True, True]).show()
- C. df.sort("age", "salary", ascending=[False, True]).show()
- D. df.orderBy("age", "salary", ascending=[True, False]).show()
Answer:
D
Explanation:
To sort a PySpark DataFrame by multiple columns with mixed sort directions, the correct usage is:
python
CopyEdit
df.orderBy("age", "salary", ascending=[True, False])
age will be sorted in ascending order
salary will be sorted in descending order
The orderBy() and sort() methods in PySpark accept a list of booleans to specify the sort direction for
each column.
Documentation Reference:
PySpark API - DataFrame.orderBy
Question 14
What is the difference between df.cache() and df.persist() in Spark DataFrame?
- A. Both cache() and persist() can be used to set the default storage level (MEMORY_AND_DISK_SER)
- B. Both functions perform the same operation. The persist() function provides improved performance as its default storage level is DISK_ONLY.
- C. persist() - Persists the DataFrame with the default storage level (MEMORY_AND_DISK_SER) and cache() - Can be used to set different storage levels to persist the contents of the DataFrame.
- D. cache() - Persists the DataFrame with the default storage level (MEMORY_AND_DISK) and persist() - Can be used to set different storage levels to persist the contents of the DataFrame
Answer:
D
Explanation:
df.cache() is shorthand for df.persist(StorageLevel.MEMORY_AND_DISK)
df.persist() allows specifying any storage level such as MEMORY_ONLY, DISK_ONLY,
MEMORY_AND_DISK_SER, etc.
By default, persist() uses MEMORY_AND_DISK, unless specified otherwise.
Reference:
Spark Programming Guide - Caching and Persistence
Question 15
A data analyst builds a Spark application to analyze finance data and performs the following
operations: filter, select, groupBy, and coalesce.
Which operation results in a shuffle?
- A. groupBy
- B. filter
- C. select
- D. coalesce
Answer:
A
Explanation:
The groupBy() operation causes a shuffle because it requires all values for a specific key to be
brought together, which may involve moving data across partitions.
In contrast:
filter() and select() are narrow transformations and do not cause shuffles.
coalesce() tries to reduce the number of partitions and avoids shuffling by moving data to fewer
partitions without a full shuffle (unlike repartition()).
Reference:
Apache Spark - Understanding Shuffle