comptia da0-001 practice test
Data+
Question 1
A data analyst needs to calculate the mean for Q1 sales using the data set below: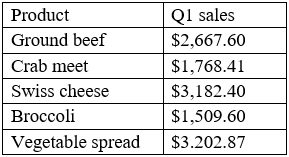
Which of the following is the mean?
- A. $2,466.18
- B. $2,667.60
- C. $3,082.72
- D. $12,330.88
Answer:
C
Explanation:
The mean is the average of all the values in a data set. To calculate the mean, we add up all the
values and divide by the number of values. In this case, the mean for Q1 sales is ($2,000 + $3,000 +
$4,000 + $2,500 + $3,500) / 5 = $3,082.72 Reference: CompTIA Data+ Certification Exam Objectives,
page 9
Question 2
A customer list from a financial services company is shown below: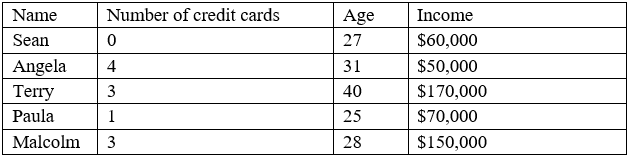
A data analyst wants to create a likely-to-buy score on a scale from 0 to 100, based on an average of
the three numerical variables: number of credit cards, age, and income. Which of the following
should the analyst do to the variables to ensure they all have the same weight in the score
calculation?
- A. Recode the variables.
- B. Calculate the percentiles of the variables.
- C. Calculate the standard deviations of the variables.
- D. Normalize the variables.
Answer:
D
Explanation:
Normalizing the variables means scaling them to a common range, such as 0 to 1 or -1 to 1, so that
they have the same weight in the score calculation. Recoding the variables means changing their
values or categories, which would alter their meaning and distribution. Calculating the percentiles of
the variables means ranking them relative to each other, which would not account for their actual
magnitudes. Calculating the standard deviations of the variables means measuring their variability,
which would not make them comparable. Reference: CompTIA Data+ Certification Exam Objectives,
page 10
Question 3
Which of the following actions should be taken when transmitting data to mitigate the chance of a
data leak occurring? (Choose two.)
- A. Data identification
- B. Data processing
- C. Data Reporting
- D. Data encryption
- E. Data masking
- F. Fata removal
Answer:
D,E
Explanation:
Data encryption and data masking are two actions that can be taken when transmitting data to
mitigate the chance of a data leak occurring. Data encryption means transforming data into an
unreadable format that can only be decrypted with a key. Data masking means hiding or replacing
sensitive data with fictitious or anonymized data. Both methods protect the confidentiality and
integrity of the data in transit. Reference: CompTIA Data+ Certification Exam Objectives, page 13
Question 4
A data analyst has been asked to organize the table below in the following ways:
By sales from high to low -
By state in alphabetic order -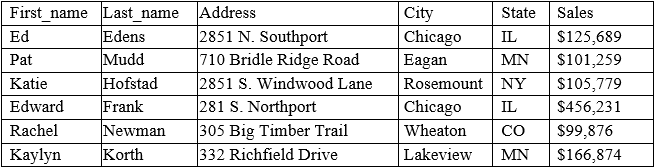
Which of the following functions will allow the data analyst to organize the table in this manner?
- A. Conditional formatting
- B. Grouping
- C. Filtering
- D. Sorting
Answer:
D
Explanation:
Sorting is the function that will allow the data analyst to organize the table in the desired manner.
Sorting means arranging the data in a specific order, such as ascending or descending, based on one
or more criteria. Sorting can be applied to any column in the table, such as sales or state. Reference:
CompTIA Data+ Certification Exam Objectives, page 11
Question 5
Which of the following BEST describes the issue in which character values are mixed with integer
values in a data set column?
- A. Duplicate data
- B. Missing data
- C. Data outliers
- D. Invalid data type
Answer:
D
Explanation:
The invalid data type is the best description for the issue in which character values are mixed with
integer values in a data set column. Invalid data type means that the data does not match the
expected or required format or structure for a given variable or attribute. For example, if a columnis
supposed to store numerical values, but some rows contain text values, then those rows have an
invalid data type. Reference: CompTIA Data+ Certification Exam Objectives, page 10
Question 6
Which of the following is a process that is used during data integration to collect, blend, and load
data?
- A. MDM
- B. ETL
- C. OLTP
- D. BI
Answer:
B
Explanation:
ETL is a process that is used during data integration to collect, blend, and load data. ETL stands for
extract, transform, and load, which are the three main steps involved in moving data from different
sources to a common destination, such as a data warehouse or a data lake. ETL helps to consolidate
and standardize data for analysis and reporting purposes. Reference: CompTIA Data+ Certification
Exam Objectives, page 12
Question 7
An analyst has received the requirements for an internal user dashboard. The analyst confirms the
data sources and then creates a wireframe. Which of the following is the NEXT step the analyst
should take in the dashboard creation process?
- A. Optimize the dashboard.
- B. Create subscriptions.
- C. Get stakeholder approval.
- D. Deploy to production.
Answer:
C
Explanation:
Getting stakeholder approval is the next step the analyst should take in the dashboard creation
process, after confirming the data sources and creating a wireframe. Stakeholder approval means
getting feedback and validation from the intended users or clients of the dashboard, to ensure that it
meets their expectations and requirements. This step helps to avoid rework and ensure customer
satisfaction. Reference: CompTIA Data+ Certification Exam Objectives, page 14
Question 8
A data analyst has been asked to derive a new variable labeled “Promotion_flag” based on the total
quantity sold by each salesperson. Given the table below: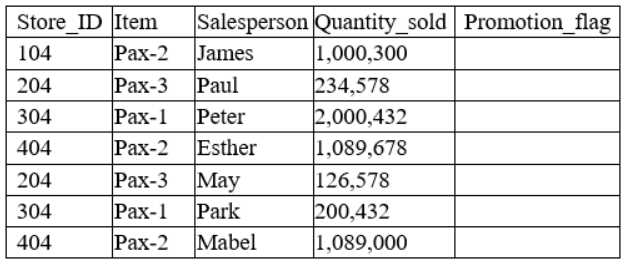
Which of the following functions would the analyst consider appropriate to flag “Yes” for every
salesperson who has a number above 1,000,000 in the Quantity_sold column?
- A. Date
- B. Mathematical
- C. Logical
- D. Aggregate
Answer:
C
Explanation:
A logical function is a type of function that returns a value based on a condition or a set of
conditions. For example, the IF function in Excel can be used to check if a certain condition is met,
and then return one value if true, and another value if false. In this case, the data analyst can use a
logical function to check if the Quantity_sold column is greater than 1,000,000, and then return “Yes”
if true, and “No” if false. This would create a new variable called Promotion_flag that indicates
whether the salesperson has sold more than 1,000,000 units or not. Reference: CompTIA Data+
Certification Exam Objectives, Logical functions (reference)
Question 9
Given the diagram below: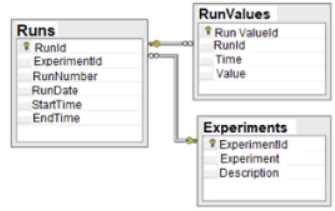
Which of the following data schemas shown?
- A. Key-value pairs
- B. Online transactional processing
- C. Data Lake
- D. Relational database
Answer:
D
Explanation:
A relational database is a type of database that organizes data into tables, where each table has a
fixed number of columns and a variable number of rows. Each row in a table represents a record or
an entity, and each column represents an attribute or a property of that entity. The tables are linked
by common fields, called keys, which enable the database to establish relationships between the
data. A relational database schema is a diagram that shows the structure and organization of the
tables, columns, keys, and constraints in a relational database. The diagram given in the question
isan example of a relational database schema, as it shows two tables: “Runs” and “Experiments”,
with their respective columns, data types, and primary keys. The “Runs” table also has a foreign key
that references the “ExperimentId” column in the “Experiments” table, indicating a relationship
between the two tables. Therefore, the correct answer is D. Reference: What is a database schema? |
IBM, Database Schema - Javatpoint
Question 10
A company’s marketing department wants to do a promotional campaign next month. A data analyst
on the team has been asked to perform customer segmentation, looking at how recently a customer
bought the product, at what frequency, and at what value. Which of the following types of analysis
would this practice be considered?
- A. Prescriptive
- B. Trend
- C. Gap
- D. Custer
Answer:
D
Explanation:
Customer segmentation is a type of cluster analysis, which is a method of grouping data points based
on their similarities or differences. Cluster analysis can help identify patterns and trends in the data,
as well as target specific groups of customers for marketing purposes. One common technique for
customer segmentation is RFM analysis, which stands for recency, frequency, and monetary value.
This technique assigns a score to each customer based on how recently they bought the product,
how often they buy the product, and how much they spend on the product. These scores can then be
used to create clusters of customers with different characteristics and preferences. Therefore, the
correct answer is D. Reference: Cluster Analysis - Statistics Solutions, RFM Analysis: The Ultimate
Guide for Customer Segmentation
Question 11
A publishing group has requested a dashboard to track submissions before publication. A key
requirement is that all changes are tracked, as multiple users will be checking out documents and
editing them before submissions are considered final. Which of the following is the BEST way to
meet this stakeholder requirement?
- A. Display the version number next to each submission on the dashboard.
- B. Present a data refresh date at the top of the dashboard.
- C. Confirm the dashboard is adhering to the corporate style guide.
- D. Use permissions to ensure users only see certain versions of the submissions.
Answer:
A
Explanation:
A static report is a type of report that shows a snapshot of data at a specific point in time. A static
report does not change or update automatically, unless the data source is refreshed or the report is
regenerated. A static report is suitable for situations where the data does not change frequently or
where historical data is needed for comparison or analysis. In this case, the data analyst is asked to
create a sales report for the second-quarter 2020 board meeting, which will include a review of the
business’s performance through the second quarter. The board meeting will be held on July 15, 2020,
after the numbers are finalized. This means that the data analyst does not need to show real-time or
dynamic data, but rather a fixed and accurate view of the sales data for the second quarter.
Therefore, a static report would be the best way to meet this stakeholder requirement. Therefore,
the correct answer is A. Reference: What are Static Reports? | Sisense, Static vs Dynamic Reports -
What’s The Difference? | datapine
Question 12
The number of phone calls that the call center receives in a day is an example of:
- A. continuous data.
- B. categorical data.
- C. ordinal data.
- D. discrete data.
Answer:
D
Explanation:
Discrete data is a type of data that can only take certain values, usually whole numbers or integers.
Discrete data can be counted, but not measured. For example, the number of students in a class, the
number of books in a library, or the number of phone calls that a call center receives in a day are all
examples of discrete data. Discrete data is different from continuous data, which can take any value
within a range, and can be measured with precision. For example, the height of a person, the weight
of a fruit, or the temperature of a room are all examples of continuous data. Therefore, the correct
answer is D. Reference: [Discrete vs Continuous Data: Definition and Examples - Statistics How To],
[Discrete Data - Definition and Examples | Math Goodies]
Question 13
A data analyst is asked to create a sales report for the second-quarter 2020 board meeting, which
will include a review of the business’s performance through the second quarter. The board meeting
will be held on July 15, 2020, after the numbers are finalized. Which of the following report types
should the data analyst create?
- A. Static
- B. Real-time
- C. Self-service
- D. Dynamic
Answer:
A
Explanation:
A dynamic report is a type of report that shows data that changes or updates automatically based on
certain criteria or parameters. A dynamic report can allow users to interact with the data, filter it,
drill down into it, or visualize it in different ways. A dynamic report is suitable for situations where
the data changes frequently or where real-time or near-real-time data is needed for decision making
or analysis. In this case, the data analyst is asked to create a sales report for the second-quarter 2020
board meeting, which will include a review of the business’s performance through the second
quarter. The board meeting will be held on July 15, 2020, after the numbers are finalized. This means
that the data analyst does not need to show real-time or dynamic data, but rather a fixed and
accurate view of the sales data for the second quarter. Therefore, a static report would be the best
way to meet this stakeholder requirement. Therefore, the correct answer is A. Reference: [What are
Dynamic Reports? | Sisense], Static vs Dynamic Reports - What’s The Difference? | datapine
Question 14
Which of the following would be considered non-personally identifiable information?
- A. Cell phone device name
- B. Customer’s name
- C. Government ID number
- D. Telephone number
Answer:
A
Explanation:
Non-personally identifiable information (non-PII) is any data that cannot be used to identify, contact,
or locate a specific individual, either alone or combined with other sources. Non-PII can include
aggregated statistics, anonymous data, device identifiers, IP addresses, cookies, and other types of
information that do not reveal the identity or location of a person. Cell phone device name is an
example of non-PII, as it does not reveal any personal information about the owner or user of the
device. Therefore, the correct answer is A. Reference: What is Non-Personally Identifiable
Information (Non-PII)? | Definition and Examples, What is Personally Identifiable Information (PII)? |
Definition and Examples
Question 15
Which of the following is a common data analytics tool that is also used as an interpreted, high-level,
general-purpose programming language?
- A. SAS
- B. Microsoft Power BI
- C. IBM SPSS
- D. Python
Answer:
D
Explanation:
Python is a common data analytics tool that is also used as an interpreted, high-level, general-
purpose programming language. Python has a simple and expressive syntax that makes it easy to
read and write code. Python also has a rich set of libraries and frameworks that support various tasks
and applications in data analytics, such as data manipulation, visualization, machine learning, natural
language processing, web scraping, and more. Some examples of popular Python libraries for data
analytics are pandas, numpy, matplotlib, seaborn, scikit-learn, nltk, and beautifulsoup. Python is
different from other data analytics tools that are not programming languages but rather software
applications or platforms that provide graphical user interfaces (GUIs) for data analysis and
visualization. Some examples of these tools are SAS, Microsoft Power BI, IBM SPSS. Therefore, the
correct answer is D. Reference: [What is Python? | Definition and Examples], [Python Libraries for
Data Science]